Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
ongoing by Tim Bray
ongoing fragmented essay by Tim BrayAutomata, Built For Comfort or Speed 14 Jun 2026, 2:00 pm
It’s been a while. February was the last entry in this Quamina Diary; I never stopped working on it but there hasn’t been much blogworthy. This piece offers a progress update for those who’ve been entertained by Quamina, and also a pleasing (well, to me anyhow) dip into finite-automata theory and practice. With numbers and graphs and a bluesman!
Since it’s been so long, here’s what Quamina, a Go-language library, does: You can add “Patterns” to a Quamina instance, they match the values of fields in JSON objects, and then you show Quamina a JSON “Event” and it’ll tell you which Patterns matched it. It’s pleasingly fast and in many cases the speed is not strongly affected by the number of Patterns you’re trying to match.
The last release, V2.0.2 back in March, marked the arrival of a reasonably-full regular-expression dialect into Quamina’s
pattern language, so you can say, for example, that the Filename field has to match
map-[0-9]+.(png|pdf|jpe?g).
Regular expressions were a lot of work and a lot of fun.
Finite-automaton wrangling
Quamina works by compiling the Patterns into finite automata, then matching the Event fields by traversing them. To handle multiple Patterns, Quamina merges the automata together, a technique that’s been well-studied in Computer Science for decades. From a set-theoretic point of view it’s a union; an OR through Boolean lenses. There’s really no limit in theory for how many patterns you can merge, and Quamina has no problem at all with thousands.
There are two flavors of finite automata: Deterministic (DFAs) and Nondeterministic (NFAs). If you have a university degree in CS they probably made you study this at some point. Weirdly, many people find the subject boring.
I’m not going to explain the differences, if you want to know it’s easy to look up, and anyhow the story I want to tell doesn’t need it. Here’s what the story needs:
To implement wildcards and regular expressions, you need NFAs.
Matching data with DFAs is generally a whole lot faster than with NFAs.
There’s a well-known algorithm for transforming any NFA into a DFA that matches exactly the same data. It’s really a lovely algorithm, you want to tickle it under its adorable little chin.
In some cases, the algorithm can be brutally expensive, along the lines of
O(2N).
The benchmark from Hell
I found a data file in the Wordle source code with 13K or so 5-letter words. I inserted a * at a random location
in each. To illustrate, here are the first five results: aah*ed, aalii*, *aargh,
aar*ti, and abaca*.
The benchmark is, you load these into a Quamina instance and measure how fast it is to load them, how much memory the merged NFA consumes, and how many Patterns per second you can match. Then you repeat the exercise, converting each NFA into a DFA.

I loaded 10K Patterns in NFA form, but the NFA-to-DFA conversion got so brutal my patience only allowed me to load and measure 300 in DFA form. (Which kind of gives away this article’s punchline but stick with me, the details are fun).
Willie Dixon
He was a famous bluesman and I need help from him to explain my APIs.
Quamina’s latest PR adds APIs
to turn the NFA-to-DFA conversion on and off; it’s off by default. There are two MatcherBuildMode values,
BuiltForComfort and BuiltForSpeed. Which are out-takes from Willie’s 1959 song Built For
Comfort, and the lyrics go like this:
Some people built like this, some people built like that,
The way I’m built, don’t you call me fat
Cause I’m built for comfort, I ain’t built for speed
…
Willie was a big guy, way over six feet and not exactly slender. I know this because I interviewed him once, but that’s another story. Lots of others have covered this tune, most of whom are, um, well-rounded.
Speaking of which… here is Quamina’s memory consumption in NFA mode.

The memory cost is pretty well linear in the number of patterns. For 10K patterns Quamina uses something over 25M which feels kind of reasonable to me.
Here’s the story for DFAs.

I haven’t run regressions or anything and I don’t think that’s actually O(2N), but the second
derivative is solidly positive, which in simple English means “doesn’t scale”.
Now let’s look at the Pattern-addition time for NFAs and then DFAs.


Once again, the NFA cost increases more or less linearly (albeit interestingly jagged), while for DFAs, look at that second derivative. This was what eventually made my patience give out and limit the DFA run to 300 Patterns.
Now let’s look at the payoff, the number of Event matches/second in NFA- and DFA-land.


The NFA performance degrades at something like O(N-1), but DFAs just don’t care. After a few lurches
it rolls along at between 500 and 600K/second. Not bad, and based on experience with huge DFAs that were built from
exact string matches, my belief is that the matching speed would eventually drift down, but slowly, not remotely a linear
function of the number of Patterns.
Not just pictures but numbers too
It was maybe a little unfair to compare 10K NFAs against only 300 DFAs, so let’s focus in. (This is on a 2023 M2 MacBook Pro.)
| 300 Patterns | |||
|---|---|---|---|
| Memory | Add-Pattern time | Matches/sec | |
| NFAs | 860K | 0.1 ms | 222K |
| DFAs | 45M | 7.7 sec | 404K |
| 10K Patterns | |||
| NFAs | 27M | 2.3 ms | 21K |
That’s pretty shocking stuff. 10K NFAs occupy less memory than the DFAs equivalent to 300 NFAs. And the Add-Pattern time, which is totally dominated by the NFA-to-DFA logic, is getting into intractable territory. So why would anyone mess with the DFA conversion? Because it matches data twice as fast!
Practical advice for Quamina users
First, if you’re a normal human being and only matching a handful of patterns against a few Events/second, ignore all this and just take the defaults, Quamina latency will vanish in the static. If you’re matching lots of numeric and string values against many Events/second, don’t lose any sleep, keep on packing in the Patterns and Quamina probably won’t slow down enough for you to even notice.
In theory you’d eventually get into memory trouble but in my considerable experience with Quamina and its AWS-built predecessor Event Ruler, you have to be venturing into extreme-craziness territory for that to happen. (It did happen. An Amazon group added literally a million Patterns. It still ran way faster than anything else they could find.)
If you need to match wildcards or regexps, adding Patterns stops being free. The slowdown is roughly linear in the number of Patterns and isn’t actually terrible, see the data above. But if you’re using a relatively small number of regexp Patterns, go right ahead and turn on DFA conversion with “BuiltForSpeed” mode.
What next?
There’s one minor Quamina feature that’s disabled in BuiltForSpeed mode, so I’ll need to fix that and do a release.
I bet there are still low-hanging fruits that could speed up the Hell benchmark, but anyone looking for those should bear in mind that they’re fighting settled Computer Science, you’re never going to make NFA-to-DFA conversion reliably linear.
But to be honest, Quamina is starting to feel fairly feature-complete. I’d like to see a few adapters so you could use Quamina with Protobufs and Thrift and CBOR and other formats that aren’t JSON.
But in fact Quamina doesn’t have that many users; I’ve only heard from a handful. Who knows, maybe the problems you learn to solve when you’re working at AWS, and most of the groups think millions of events per seconds is an ordinary workload, aren’t widely applicable in the broader world of Open Source?
Which is to say, me working on Quamina isn’t helping that many people. At one level, I don’t care, because it’s been fun and instructive. I’d probably enjoy turning this “Quamina Diary” series into a monograph or small book if there were an interested publisher.
And thanks to everyone who’s been reading along.
Long Links (AI) 8 Jun 2026, 2:00 pm
The piece you’re now looking at exists because my latest “Long Links” curation of interesting not-lightweight material included quite a few focused on our dominant malaise, namely you-know-what, I mean it’s in the title. Plenty of people have had more than enough of this discourse and I thought I’d spare them by moving these bits over here.
Let’s start with raw data: Is AI improving people’s lives? Christine Lemmer-Webber was kind enough to ask the world or at least the Mastodon part of it, and the results weren’t subtle or nuanced at all.
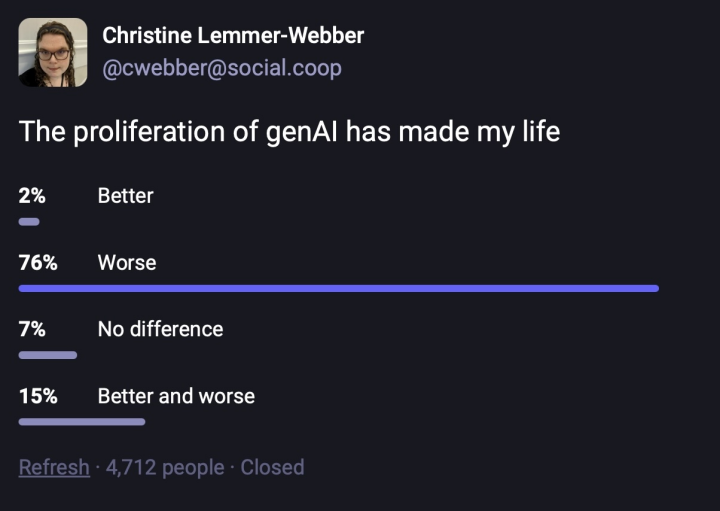
I encourage everyone to follow the link and read the conversation that broke out around that poll. It will not cheer you up.
And for my money that’s the most important take-away I’m offering today. Whether we’re using it or not, “AI” is not a thing that is making us happy.
Where I stand
Currently, I’m a contra. GenAI is being pushed by terrible people who are trafficking in lies and abusing the planet, and should their far-fetched dreams come true the consequences would be terrible for most people. Because they want to disempower knowledge workers, remove them from the economy, and cast them loose on the tender mercies of the market.
The reason for that “Currently” in the paragraph above is that we’re living in a liminal space where everybody I know who has any brains is convinced that there’s a bubble inflated by trillions of dollars of speculative and likely doomed investment. It’s very near popping, and the consequent miasma of fear and greed makes it absolutely impossible to have a reasonable discussion of what GenAI might be good for and might not.
The onrushing terrible trio of IPOs (SpaceX, OpenAI, Anthropic) feels to me like when there’s a 9.2 earthquake 50km offshore and so far no tsunami has been detected but everyone’s glancing nervously at the horizon.
So anyhow, for now I’m not going to use any GenAI tools myself. Post-pop, it may develop that there ways it can be ethical and useful, albeit at an immensely smaller scale than the LLM edgelords are pitching. We’ll see.
I have been accepting human-curated Claude-driven PRs on my Quamina hobby project. For which I’ve already been called a Nazi by someone whose views I take seriously. (But I really don’t think I am.) I do think that when the dust settles, there will be a role for LLMs in software development, but I also think we haven’t figured out yet what it is. I absolutely do not believe for a second the claims of 10x improvements in “productivity” (I do not think that word means what you think it means).
Having said all that, here are morsels of gold from the torrent of AI dross that wants to flood every fucking one of my input channels.
Critiques
Bram Cohen says The Cult Of Vibe Coding Is Insane. Yup. Kyle Kingsbury writes a long sad series: The Future of Everything is Lies, I Guess. He seems to come out about where I do: Not going there for now.
Dr Bethan Tovey-Walsh offers us The Community is the Achievement; the Achievement is the Community, subtitled An ethical love-letter to distributed technology communities. It’s long and defies summarization, but light-hearted, a pleasant read. Its bottom line is, and I quote: “The right thing, in my view, for tech communities and projects to do is to reject contributions of LLM-generated content.” Recommended even if you disagree.
Wow, here’s one that hits hard, academic output from big-name universities: AI Assistance Reduces Persistence and Hurts Independent Performance. What’s shocking is that it doesn’t take that much AI exposure before the symptoms start appearing.
Corey Quinn’s day job is helping people lower their AWS bills, and he markets it (very successfully) by writing snark-heavy essays on more or less anything cloud-related generally and AWS-focused specifically. It seems he’s got a new AI-oriented platform called “Artificial Confidence”, whence Artificial Confidence: xAI, the Neocloud. Corey is a gifted polemicist and xAI is a soft target. It does not come off well. Since xAI is a major chunk of the looming SpaceX IPO, this piece is highly relevant, possibly to your retirement savings.
I know Appearing Productive in The Workplace was widely posted and quite likely you’ve seen it; if you haven’t, go read it and if you already have, another visit might be beneficial.
Bug finding
From the Linux-kernel world, there’s AI bug reports went from junk to legit overnight, says Linux kernel czar and Significant raise of reports, which says about the same thing with a couple of plausible and important conclusions. There was a report about Linus Torvalds criticizing the inflow, (see here) but it turns out he was after the practice of LLM-script kiddies reporting them to the “secret” mailing list. Which is a no-brainer because if an LLM that everyone can run finds a bug, then it’s obviously not a secret.
Anyhow, looks like GenAI can be put to good use finding vulnerabilities.
War stories and advice
Assuming that post-bubble it becomes possible to use AI in coding without being called a Nazi, we have to face the fact that we really don’t have any consensus best practices for doing that. So I enjoy reading narratives of people who describe what they did, in detail (no architecture astronautics) what worked, and what didn’t.
Lalit Maganti’s Eight years of wanting, three months of building with AI which centers around building an SQL parser that exactly matches SQLite’s. That’s a freaking hard problem and I think Maganti’s narrative has pointers to a plausible future.
The redoubtable and loud-voiced Daniel Stenberg of Curl fame offers us A Human In Control, which says about what the title does, with feeling.
Nelson Minar posted First impressions of Jules, Google’s coding agent; this will probably be interesting to those living in the Claude or Copilot territory.
Rails is regarded as a good framework for building certain classes of Web site. Normally, it is considered as Ruby code and executed using the Ruby runtime. Sam Ruby (the surname is a coincidence) has been doing remarkable work arranging for Rails app specifications to be executed by other runtime platforms, notably including Typescript, Rust, and Elixir with no ruby (except for Sam) involved.
He relies heavily on GenAI and describes his findings in The Drucker Inversion. It’s deep, thoughtful stuff.
Joe Magerramov’s The Valley of Calm makes perfect sense to me because I spent some years inside AWS. His basic point is that if GenAI ends up increasing the number of commits, your CI/CD pipeline is likely to cave under pressure. Looks to me like he’s right, and his proposals for how to address the problem sound plausible. “Plausible” isn’t good enough, this is another area where we just don’t yet know what the best practices are, and there’s only one way to find out.
Hey, two AWS people in a row: Brooke Jamieson is a Developer Advocate, what I used to be at Google. Make Your Coding Agent Opinionated begins “I’ve been using coding agents daily for over a year across Kiro, Claude Code, Cursor, and Codex.” Here are her lessons.
That’s all folks
We can argue with each other about how best (or if at all) to use this technology. Maybe it’s all irrelevant or (I think) at best a side-show until the AI-bubble greed and fear dissipates. Which can’t come too soon. Maybe it’s useful to work on the problem in standby mode while we wait for the bubble to collapse.
I’m pretty sure it will.
Long Links (AI-free) 5 Jun 2026, 2:00 pm
Hey everyone, I know you’re overloaded because everything has become overly efficient. Long-form reading or writing or art or music, who’s got time for that? Fortunately there are those who still do and here’s some if it. I hope one or two of the link targets can chisel their way into your jammed schedule and bring with them joy or rage or another appropriate feeling. Today’s curation has a lot of books and music and way more humor than usual. Also, a good electric wok.
Now, let’s all take a couple of breaths and gingerly approach the A-word, namely “AI” (as understood in 2026). Which is occupying much more of my attention and cognition than I would like, and there are gems embedded in the flood; granted, sparsely but they still add up. I respect that many of you will have just fucking had it with that subject. So I shuffled that material off into Long Links (AI), which you can drop by (or not) as you please.
Books
One of the weirdest and flawed but still good things I’ve read this year is The Luminaries, written by Eleanor Catton back in 2013, a pretty dark tale of murder and theft and love and oppression in a not-so-great corner of New Zealand during an 1866 gold rush. Really super intense and hard to put down; even though it’s 900+ pages I never got bored. But freakishly complicated and I was left puzzled by multiple plot elements. Fortunately (yay Internet!) there’s Deconstructing The Luminaries, an explainer.
Other recent books: Platform Decay, minor Murderbot, but still worth reading. The Incandescent by Emily Tesh, yet another highschool-for-magic book, only with the grownups in the foreground and the kids behind them. Way more fun than the last few instances of that genre. Also, sex. Finally worth mentioning: The Everlasting by Alix Harrow, which started slow but eventually got a real grip on me; recommended.
I was in the library today and I always cruise past the “featured” table, where I saw Nobody’s Girl by Epstein victim Virginia Giuffre (R.I.P.) and Empire of AI, Karen Hao’s huge takedown of OpenAI and Altman. But I just now do not have the spoons. Maybe later.
Hmm, they tell me men can write books too. Must look into some.
Political economy
I and many others are deeply discontented with the current flavor of late-stage capitalism, that “late-stage” a conscious callout to terminal illness. So do we really want to do away with Capitalism as such, or retain it but try to regulate away inhumane behaviors and effects? Or what? Let’s not forget that there are still people out there proud to call themselves Socialists and their take is that Capitalism can’t be fixed and must be replaced. With what?
Anyhow, if you want to hear what these people are saying the place to go is Jacobin. I’m not a regular visitor but when I do drop by I’m starting to hear the phrase “market socialism”. Thus How Socialism in the 21st Century Could Work. The tone is kind of nonspecific and academic but it’s part of a conversation that I think the (large, growing) mad-at-Capitalism demographic needs to have.
Speaking of the pathologies of late-stage capitalsm, Paul Krugman’s Bezos, Backlash and Zombies describes a Bezos TV appearance in which Jeff said some really dumb things. Which is a bit surprising because while fewer and fewer people seem to like him, most people think he’s pretty smart. Krugman tears apart Bezos’s deep and broad misunderstanding of how taxation works. He attributes it to what he calls “Billionaire Brain”; the notion is plausible. The discussion goes on into popular perceptions of business in general, technology in particular. And (*sigh*) AI. Good stuff.
People like reading books on screens and most public libraries now support that. I believe a high proportion of such loans go through Libby, which is what I use. But the publishers don’t actually sell e-books to libraries, they rent them, a price for a fixed number of loans. And as you might expect, that price keeps going up, to the point that public libraries all over the world are hurting. So, Library Orgs Urge Big Five to Address Digital Pricing. Paper books are looking better and better.
It turns out that America’s capital is a good experimental platform for crime research. Check out Washington, D.C.’s crime decline and its lessons for American policing from the Niskanen Center. Guess what: There’s little correlation between the number of cops and the amount of crime. Also, when Trump sent in the National Guard to stand around with their thumbs up their asses being visible, the effect was tiny and only on “property crimes of opportunity”. Does that mean graffiti?
Funnies
Staying in the political lanes, here’s an evening briefing from Talking Points Memo, my favorite US-Politics blog. It’s got two unintentional jokes. First of all, this little sequence on the subject of Trump wanting to print a $250 bill with his face on it.
… two political appointees at the Treasury Department … repeatedly urged staff at the agency’s Bureau of Engraving and Printing to prepare prototypes of the note, according to the employees, who said the move raised concerns because federal law currently allows only deceased people to appear on bills.
There’s more than one way to read that… I’m suddenly starting to see the advantages of printing that bill.
Then, a little further down, it turns out JD Vance gave a speech at the Air Force Academy, from which:
So as AI transforms the battlefield — in some ways positively, in some ways not — I ask that you be jealous and selfish about your role as a decision-maker in warfare,” he continued. “Use technology to make you better, but never submit to it. You are the masters of warfare…
Yeah well Bob wrote a whole song about Masters Of War and got the trade-offs about right. JD’s cluelessness is mountainous.
OK, here’s an organized-crime story that makes me smile because it’s just so hilariously blatant. It’s like this: Worldwide, cricket is a big-money sport. Any readers who come from India or English-speaking southern-hemisphere countries are nodding because well of course. Cricket in Canada is not a big deal; our South Asian and Caribbean immigrants may be seen playing in the park on weekends with nobody but spouses and kids are watching.
Nonetheless the International Cricket Council has been sending a few million dollars a year to Cricket Canada to develop the sport hereabouts. But no longer. It seems that Cricket Canada has been a comical hotbed of theft, fraud, extortion, and match-fixing. Recently gunshots were fired at its president’s house. The TV segments have been hilarious, with leaders of Canada’s cricket establishment sweatily denying everything while looking over their shoulders. Anyhow, if you like colorful true-crime drama, start with Cricket Canada surprised after “unexpected” suspension by governing body over breaches of membership.
Photography
I visit Petapixel more days than not; it’s got the goods in the world of cameras and photography. There are solid camera and lens reviews, and a lot of focus on individual photographers. Here’s The photographer who never stopped chasing the perfect shot (and, on the evidence, got plenty). Next, Jeff Austin has been shooting the same parts of Tokyo through vintage glass for decades; he contributed Twenty Years, One City: What Tokyo Taught Me About Patience and Glass and has a Web site, Tokyo Forgeries.
Not just metal and glass; here’s an interesting camera bag: The Pilot 88 Is a Limited Edition Wotancraft Messenger Designed by Chris Niccolls. Finally, the story of Edith Tudor-Hart, in The Hidden History of a British Female Photographer Turned Soviet Agent.
Disturbing Evidence
Now, I said I liked Petapixel, and I do. But there’s a dark side; one can’t help notice the many many stories about the terrible things that happen to photographers. Then there’s the sub-genre of terrible things that happen in the context of wedding photography, which seems a swamp of suffering and pain. Well… why not both? Wedding Photographer Seriously Injured After Being Stabbed by Guest. I mean, it goes on and on: Photographer Bitten by “Shark or Sea Lion” During Surf Competition and Woman Pleads Guilty to Manslaughter After Gun-Themed Polaroid Photo Shoot Ends with Photographer’s Death! Mommas, don’t let your babies grow up to be photogs.
Personalities & misc
In the world of Big Biz generally and Big Tech specifically, PR leaders are very near the center of everything. CxOs are basically never allowed to say anything that isn’t carefully scripted in advance; PR does the scripting. When somebody fucks up and things (including the share price) go off the rails, PR owns the problem.
During the years when I was a blogging in a relatively unsupervised way while employed in BigTech, I became pretty intimate with some of those PR folks. I remember not too long after I joined Amazon, my manager, a really good person who’d gone to lots of work to hire me, grabbed me in the hallway and said “PR is pissed about what you wrote about Microsoft” and I said “Don’t worry, talking PR people down off the ledge is one of my core competences.” He looked worried: “Well, good luck.” But it was OK.

Anyhow, Claire Stapleton was in PR at Google during the glory years, and was close to the center of things. She got laid off in 2023 and wrote game over - some thoughts on layoffs and life. A few things in there widened my eyes and I suspect they’ll do the same for anyone else who’s been in the Google ecosystem. Anyhow, recently she wrote a book which I have to say looks pretty promising.
JA Westenberg’s On wintering speaks to me. One of the nice things about being (mostly) retired is I get lots of time for this. It’s hard to see how the machineries of Late Capitalism could allow this kind of space though; another reason to find something better.
At least once a year I point excitedly at something by Paul Ford; this time it’s Canons. Beautiful stuff.
Product pitch
For the last few years, we’ve had induction stovetops, which I totally love: Responsive, hot, easy to clean, low carbon load. but, I like to stir-fry and you can’t really balance a wok on an induction top. So we picked up an Abangdun 1700W 100V~185V Induction Cooktop Concave Curved Surface 2026 New Electric Stove Wok. It’s great; I stir-fry a couple times a month and get good reviews. Its built-in fan is kinda noisy.
Music
Recently I ran across The Sleeveens, Irish punks in Nashville. I said “punk” and I mean it, it’s nearly the pure stuff, somewhere on the Clash-to-Ramones axis, and like those bands, the tunes are good, and like the Clash, the lyrics are political and gonna make you sit up. Their recent outing National Anthem is just one banger after another. My favorites are If I Was A Casual and Cowboy Queen and then there’s the title track, which begins “Burn your fuckin’ country to the ground in the name of love…” oh yeah.

Now let’s lean into a fertile field of musicological scholarship: Guitar solos! Rolling Stone let their dimbulb flag fly with The 100 Greatest Guitar Solos Of All Time, which unforgivably omits Ry Cooder on Amandrai, Susan Tedeschi on Pity the Fool, David Lindley on Do Ya Wanna Dance, Neil Young on Love To Burn, Megan Lovell on Preachin’ Blues, also [Tim, enough -Ed.].
But wait, there’s more. Not to be outdone, Consequence (of which I know nothing) came up with 70 Best Guitar Riffs of the 21st Century (So Far), which is full of smiles. I have to confess that I’d heard less than 10% of these.
But anyhow Japanese metallistas Boris, about whom I’ve blogged not once, not twice, but thrice, are on both lists! #61 on the solos, #7 on the riffs. Which they noticed, and took a bow. Here’s Akuma no Uta and also a pretty hot live capture.
Finally, if you like Arvo Pärt and art that strains at the edges (what other kind is worth liking?) check out Robert Wilson’s “Adam’s Passion” (Music of Arvo Pärt). An hour and a half of fine music, well-played, and live human movement following Pärt’s slow pulse. Nakedness is involved.

Tech
I gather that Marcin Wichary is name to conjure with in design circles; he’s recently launched Unsung, my blog about software craft and quality and boy, it’s outstanding. A lot of it is simple celebrations of typographical or UI excellence, but what got my attention was a polite-but-savage takedown of a recent Photoshop release: Parts 1 and 2. You’ll learn a lot about how to think about UI construction by reading this.
Armin Ronacher, to whom it seems I’ve been linking a lot recently, offers Before GitHub, which to be fair contains equal parts of Current GitHub and After GitHub thinking, pretty well all of which seems good to me. Single points of failure are just bad, we should know that now, particularly when they start failing.
Finally, have a look at The Age of the Amplifier by Brian Potter at a Web site called “Construction Physics”. There are several different kinds of amplifiers, and most of the interesting ones were developed at Bell Labs during the 20th century. This is a history of that, based on the premise that “Amplifiers in general are important”. They are! The history is interesting, assuming you know what “voltage” and “current” are. It pleases me that people will still write long-winded pieces about narrow slices of history and apparently have fun doing it.
That’s all folks
Well except for the companion aggregation of Long AI-related Links.
Until next time.
XML and JSON in 2026 1 Jun 2026, 2:00 pm
The best thing about long-lived incumbent technologies like JSON and XML is that nobody really has to think about them much any more. Except for, I do occasionally, because while I’m not the inventor of either, my name’s on the front of both official specifications. Hey, it’s JSON’s 25th birthday, what a run! And what ever happened to XML? Let’s shake off the dust and have a look.
JSONiana
RFC 8259 is now nine years old and, like all the RFCs, is immutable. And, as is usually the case, a list of errata has built up over the years.
Until a few days ago, many of the errata apparently hadn’t ever been looked at for a period measured in years. Now they’ve all been rejected or accepted. Despite a couple having been marked “Held for Document Update”, nobody is interested in writing a superseding RFC. There are already enough other JSON specs [1][2] but fortunately they all say the same thing.
Which is to say, JSON is what it is and will never be improved or changed in any way. Among other things, there are literally billions of instances of JSON-reading software out there, most of them embedded in dumb low-rent devices that will never be updated.
Granted, it’s irritating that JSON doesn’t have comments (ProTip: Add a “comment” field to your messages) and makes it hard to get the commas right and doesn’t distinguish between the different flavors of numbers and doesn’t have date/time literals and allows junk Unicode. Not gonna be fixed. Which is OK because empirically, it’s good enough. Probably a few megabytes of JSON will have flowed back and forth between your phone or computer and the Net while you’ve been reading this.
Of course, there’s YAML and TOML and CBOR and Thrift and Avro and Protobufs and Markdown and more. Maybe for your app one of them is a better choice than JSON.
Oh wait, I forgot, there is a new thing: Work is under way to write an RFC specifying JSON Schema, which is quite widely used but not well specified. Good luck to the people working on that; I’m not one of them.
The best thing about JSON is nobody really has to think about it any more.
XMLitude
Last month, on the “xml-dev” mailing list, Elliotte Rusty Harold remarked, on the subject of XML generally: “Count me as one of the people who thinks it’s mostly obsolete and ultimately a failed experiment. People don’t want or need markup that’s designed to make documents easier for computers to read but harder for humans to write.”
I replied and here’s an expanded version of what I wrote:
Irrespective of the current uptake, and seen as an experiment, XML has been a success. It proved that:
You can have a data interchange format that is radically independent of your computer architecture, operating system, programming language, and application.
The only sane text standard for modern computing is Unicode, which in practice is affordable and reasonably straightforward to use.
Prior to 1996, neither of these things were widely believed. The only “interoperable” data format was ASN.1, which is horrible and lacked quality software support. The resistance to Unicode was significant and widespread, and adoption was disappointing. Today, #1 and #2 above are the (low) bar to entry for any data packaging technology.
As for current use, I guess “office" document formats are XML for the long haul [3] [4], but relatively few developers ever have to look inside them (thank goodness). XML remains a de-facto standard for text-oriented humanities computing [5], and for legislative data processing [6][7][8]. At one point it dominated things like aircraft maintenance manuals, don’t know if that’s still true. RSS and Atom aren’t what they once were, but are far from gone; they’re how I drive my own personal news-reading. Then of course there’s EPUB; do you read books on screens? And are XBRL and UBL still things?
It is true that there are few-to-no new applications that I know of that have much reliance on XML.
Eh, it’s OK, it had a good run and moved the needle. It’ll keep a few folks employed for the foreseeable future.
Like JSON, the best thing about XML is nobody has to think about it any more. Oops, if you got here I guess you just did. Sorry bout that.
Tab Trick 24 May 2026, 2:00 pm
A person watching over my shoulder asked “How are you switching around so fast?” and I realized that while most readers here know this trick, some may not, and it’s awfully useful.
[Update: I published an earlier version of this in 2012 but have got that “How do you” question a couple times recently, so maybe it’ll still be new news to a few people.]
In all the browers I use, Command-1 takes you to your leftmost tab, command-2 to the next one over, and so on up to Command-8. Command-9 selects the rightmost tab. Also, you can right-click on a tab and “pin” it; which shrinks it down to just the favicon, and moves it as far left as it can go.
So the trick is, pin the same heavily-used tabs in the same place, and leave them there forever. In my main browser (currently Safari) it’s like this:
SMS/RCS texts, linked to my Pixel. This is a Google thing, not sure if you need to be on Android for it to work. But for those serious conversations that remain in text-land, it’s awfully nice when you can resort to an actual keyboard.
Calendar.
The local staging version of this blog, where I review and edit articles.
What you are now reading.
Blog comment review/approval.
Quamina (probably moving to Codeberg soon).
Bluesky; but it seems I never go there any more unless I’m following links from elsewhere. To be honest, not sure what I’d replace it with.
Have fun!
Declining America 19 May 2026, 2:00 pm
Recently I got an invitation from an organization I respect, to a gathering of senior people, unconference format. Yes, it’s mostly about AI. No, it doesn’t reek of boosterism. My guess is that the discussions would be relatively intelligent and unbeliever contributions would be welcome. I declined, because it’s in the USA.
Here’s the text; maybe someone in a similar situation might find it useful.
Thanks to whoever thought of me for the kind invitation, which I must regretfully decline.
I’m Canadian and as a matter of principle feeling negative about visiting a neighboring country whose leader has repeatedly threatened our sovereignty and shown massive disrespect for our nationhood. Particularly when that leader has followed up similar statements about other nations with military action.
I could probably work around that. But there’s also the issue of entering the US; if I roll up at the border and am asked to disclose my social media output, there’s a significant risk of an extremely negative outcome. I have a family to support and really can’t afford that risk.
I still consider myself a friend of your organization, and one with strong opinions about the subjects scheduled for discussion; my regrets about having to decline are entirely sincere.
—Regards, Tim
Life During Class Wartime 3 May 2026, 2:00 pm
War is bad. Don’t start one. But we’re already in a class war and we’re losing. Where by “we” I mean most people; the winning side comprises, roughly, the richest 0.1% of the population, who are morphing into a hereditary aristocracy. [I mean that, see below.] So, what to do in a war one didn’t choose?
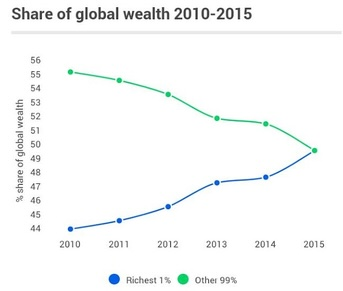
How bad is it?
It’s really bad, and getting worse fast. I recommend cruising through Wikipedia’s excellent article on Distribution of wealth; maybe jump straight to the Wealth inequality section. I’ve pulled one helpful graph, sourced from Oxfam, into the margin. The article has loads of other statements of the form “The richest X compared to the poorest Y have Z times️ as much.” The values of X, Y, and Z are uniformly saddening.
As a resident of a wealthy West-Coast New-World city, the effects of pathological inequality are in my face every day: Bentleys gleaming on the road, ragged people huddled in the rain cadging cash outside the drugstores, thousands homeless.
Why is that bad?
It’s not only sinful by any sane definition of sin, but stupid, inefficient, and damaging. I turn once again to Wikipedia: Effects of economic equality. I’ll add one pointer to an effect that is less obvious: It exacerbates the unaffordability crisis.
One effect of the increasing imbalance between the ultra-wealthy and everyone else is the emergence of, effectively, a hereditary aristocracy. “Wait!” you exclaim, “How about high income-tax rates for the wealthy, and inheritance taxes?” You might well ask. It turns out those are no longer operative. I’ll get into details about that, but first…
A parable: Grant Gustavson
I am, as previously related (see Southsiders and Fútbol Joy) a fan of the Vancouver Whitecaps Football Club (VWFC) who play in Major League Soccer. It’s affordable, light-hearted, high-drama, high-quality entertainment and has lifted my spirits notably in the recent dark years.


Vancouver Whitecaps fans bring the love
However, it appears that Vancouver’s about to lose the Whitecaps, at the whim of a Vegas-based purchaser, of whom The Athletic writes:
The potential buyer is Grant Gustavson, the son of Kentucky billionaire Tamara Gustavson and grandson of B. Wayne Hughes, founder of Public Storage, according to multiple sources with knowledge of the discussions. Forbes estimates Tamara Gustavson’s net worth at $8.5 billion.
Gustavson, 30, lives in Las Vegas. A graduate of the University of Southern California, he has been involved with the athletic department at his alma mater and helped to develop the Name, Image and Likeness (NIL) program there. He continues to work with the USC basketball program and is also involved in the management of his family’s farm, “the country’s premier thoroughbred farm with decades of storied champions throughout the stables.”
So this fucking youngster, who has life experience working at the gym at USC (where his Mom’s on the Board of Trustees) and helping out at the family farm, can reach out his mighty hand and snatch away a popular pleasure from another nation. Droit du seigneur in action.
Staying rich
I highly, highly recommend Our Tax System Should Make You Furious from the NYT. By “our” they mean America’s. First, it addresses the canard that the tax system is actually progressive; people who like things the way they are like to say “Forty percent of people pay no federal income taxes, and then the top 1 percent pay 40 percent of the income taxes.” (Tl;dr: Somewhere between highly misleading and a big fat lie.)
Second, it explains the mechanisms by which generational wealth is accumulated and preserved, effectively in perpetuity. People like Bezos and Musk pay basically no income tax, and the way they do it isn’t complicated or hard to understand.
There is actually a family of financial products called Dynasty Trusts. The first ad that popped up in response to my Web search had the marketing copy “Dynasty trusts: preserving family assets for future generations”. Or, put another way, “Dynasty trusts: Starving beggars in your neighborhood.”
Revenue from the rich
So what can we do about it? Tax expert Ray Madoff, the interviewee in the “Should Make You Furious” piece, has smart things to say. Then there’s Thomas Piketty: “Opponents of the tax on the ultra-wealthy lack historical perspective”.
The common thread is taxation of wealth not income, because the arcane abstractions of accounting make income too easy to hide. The argument is that a wealth tax of say 2%/year, starting at a threshold of a few tens of millions, won’t impair the lifestyles of the seriously wealthy, but still yield systemically important public-sector revenue
Also worth reading, from the International Monetary Fund: Game-Changers and Whistle-Blowers: Taxing Wealth. Among other things, it reports that the proportion of wealth that is hidden in one offshore tax shelter or another is pretty small, ranging from 8% in the developed countries up to 30% in poor nations. Apparently it’s harder to hide wealth than income.
Good karma
If wealth taxation won’t touch wealthy lifestyles and will help build a safer, calmer, happier society, it feels sort of irrational to oppose it. And some of the wealthy don’t. My favorite example of this is Avi Bryant. Check out I’m a Millionaire. Tax Me More, Please and Meet a millionaire who wants Canada to tax the rich. [Disclosure: I made a nice little chunk of money when my tiny investment in Avi’s startup turned into pre-IPO Twitter shares.] I’m also interested in Patriotic Millionaires, which Avi founded.
Also worth checking out: Jeff Atwood’s Stay Gold, America and Launching The Rural Guaranteed Minimum Income Initiative. So, not all of the 0.1% are The Enemy.
It’s not complicated
Around the world, governments are running up huge debts and cutting back social programs because the taxation revenue doesn’t come near the amount it requires to provide a livable society. So the choice is stark: Cut and slash deeper (read: starving beggars) or find more money. There’s lots of money out there basically just playing financial games; it needs to be put to work doing something useful.
This package of ideas should be easy to sell to voters. Of course, resistance will be ferocious and extremely well-funded. But the currently-winning side in our class war is actually a soft target. Target for what weapon, you ask? Democracy. No need for tumbrils and guillotines. Yet.
Corey’s Captives 26 Apr 2026, 2:00 pm
That’s James S.A. Corey, which is to say Daniel Abraham and Ty Franck, and their new series The Captive’s War, an in-progress work comprising 2¼ or so novels. The Coreys are of course best-known for their deservedly wildly popular The Expanse series and the subsequent success of the streaming-video version. The new series is… different. If you’re wondering whether or not you should wade in, the following is for you.
Minor and meta spoilers
Don’t worry, you can go on reading this even if you plan to read the books. Here’s a spoiler that has appeared in every public mention of the book, which I’ll give away with a quote from page 102: “I think some important scientific questions have finally been answered. Alien life exists, and they are assholes.” Which is to say, it doesn’t go well for the humans.
Now for the meta-spoilers. The novels are The Mercy of Gods and The Faith of Beasts, then there’s a novella, Livesuit. I found The Mercy of Gods a bit of a grind, and if that’s all I’d read I would have been pretty negative about this project. There is a major, major reveal partway into The Faith of Beasts that changed my whole outlook on the series; it makes the storytelling velocity really pick up. It’s a little annoying that Livesuit was published between the two full novels because it only really makes sense if you’ve finished both of them. So do like I did, and read the novella last.
I have to ask why the Coreys couldn’t have pulled the curtain aside a little earlier on. And while I’m griping, let me add that the sped-up storytelling runs into a big honking cliffhanger ending at high velocity. Harumph.
My take-away
It could go off the rails but if they can maintain their Expanse form, I suspect this series is going to be pretty great. The characters are fun to know and the narrative revolves around the great mother of all trolley-problem ethical challenges, which was not nearly resolved at cliffhanger-ending time.
Those of us who are fussy about the plausibility of future technologies (hey, Charlie Stross) should avert their eyes from the Coreys’ fairly low-effort attempts to explain how the aliens and humans in this story accomplish the things they do. Doesn’t bother me much, though.
Having said all that, this series is not cheerful stuff; I do not recommend it to those who, like many in these troubled times, are having trouble seeing the bright side of, well, anything.
Will I read the next volume?
Yep, no hesitation. And they’ve already started working on a streaming version. Unfortunately it’s going to be on Amazon Prime, which I haven’t missed since unsubscribing a couple years ago. Getting this thing on the screen is going to be an extended, difficult, task. There are multiple species of aliens that the show is going to have to absolutely nail, with emotional credibility, for the story to work. Don’t hold your breath.
Spring Evening 13 Apr 2026, 2:00 pm
On impulse, Lauren and I went out for a short walk — around just a few blocks — as the grey Spring afternoon shaded to dusk. On a second impulse, I grabbed the camera on the way out the door.
In our local community garden, here’s (I think) a chard.

That was in Vancouver’s Mount Pleasant park, small but nice and apparently never not used. Also this old blackened fruit tree, we’re a bit past the fruit-blossom peak for this year. Nice to see I’m not the only old citizen trying to brighten things up.

Now we’re walking up a locally-main street called Main Street or “The Main” if you’re trying to sound hip. Someone put work into that window! I’ve bought my daughter a couple of cool birthday presents from the store behind it. My thanks to the building across the street for providing a dark background reflection.

Back to the next block over from ours. A while ago a bunch of people were building little fairy/elf/hobbit villages at the bottoms of the big old trees. This isn’t that. What is it?

The colors of the natural surfaces are real.
Cameras
When I shot these, it was getting dark but I didn’t think much, mostly just pointed and shot. (Fiddled with the aperture dial a bit.) Then I came home and pulled them into Lightroom and didn’t need to do really anything about colors. A bit of contrast and highlights here and there. Oh, and fairly brutal cropping, especially on that fruit-tree-flowers pic. Because like I said, I didn’t think very much when I was shooting and I didn’t have to because on a Twenties camera you don’t.
I could take that heavily-cropped fruit-tree picture and print it big enough to occupy any domestic wall in your place and yeah, there’d be grain but it wouldn’t bother your eyes.
Anyhow, modern cameras are pretty great. The lowest ISO in today’s set is 2500 and the highest is 6400; the apertures range from 2.8 to 5.6. Bet you can’t tell the differences. My camera is a reasonably modern Fujifilm but not remotely bleeding-edge in camera tech. (Note: 35mm F1.4, now all the Fuji fanfolk are smiling and nodding.)
Anyhow, there are very very few photographers for whom the camera they carry is the limiting factor in the goodness of their pictures. Certainly not me.
Consider getting a camera. Used is fine, anything built in the last five years, maybe more, will effortlessly take brilliant pictures in almost any conditions. Sure, your phone can take great shots too, but the feeling of walking along with something that fits your hand and you only have to press one physical button once, that feeling, it helps you see the good pictures when they happen.
Then go out after and take a walk in the Spring dusk.
Password Manager Angst 9 Apr 2026, 2:00 pm
Our family has used 1Password for many years. Most recently 1Password 7, now at least three years out of date. We didn’t want to upgrade to the latest version, went looking for alternatives, and have been exploring Bitwarden. The best choice isn’t obvious; here’s the story thus far.
Important note: I suspect that most-to-all of the people reading this already are using a password manager. If you’re not, please, PLEASE start now. Your browser probably has an OK one built-in, which is much better than nothing. Here is a good write-up on the basics.
Our needs
They’re not fancy. The house contains Macs and Androids and Windows and an iPad. We have hundreds of accounts (some require an authenticator) and a basketfull of secure notes: Government-ID numbers, recovery codes, and so on.
1Password7 and 8
1Password had this nice feature where you could sync between devices without involving any 1Password servers, in a variety of ways. We used one of those and liked it. 1Password8 insists on storing your data (encrypted, more on that later). That always bothered me because, obviously, that repository is a top-priority juicy target for all the bad guys, who range from employees of the Chinese government to geeky narcos.
So we’ve been ignoring 1Password’s increasingly plaintive reminders that we were using years-out-of-date software and chugging along with version 7. But, early this year, they broke our sync mode on the Android app and were pretty blunt that the only way to get it back was to go to 1P8.
Alternatives
There are plenty of password managers (Let’s just say “PMs”) out there, but as a regular scanner of the landscape, it seems to me that 1Password (hereinafter “1P”) and Bitwarden (“Bw”) stand out as leaders. The rest of this piece will focus on those two. If you think I’m wrong, say so below but also please say why.
Note that Bw comes in two flavors: That offered as a subscription service by the company of the same name, or as an open-source software suite you can build and run yourself.
This is not to say that the PMs that are starting to appear built-in to browsers and OSes are worthless or unimportant, just that some of us need a little more.
The threat models
Two are obvious. The first is incompetence, like for example LastPass, who apparently left the doors more or less wide open to those bad guys I mentioned a few paragraphs ago. Complete horror-show.
The second is legal compulsion, where a government applies pressure to a PM provider to cough up our secrets. Anybody who thinks governments won’t try is fooling themselves, because they’ve repeatedly said they want to, and are eager to pass ill-considered legislation such as the CLOUD Act. So we care about that aspect a lot.
1P vs Bw: Security
I think they both have acceptably-good security postures; check out Bitwarden Security Whitepaper and About the 1Password security model.
Both of them offer to host your data outside of the US, specifically in Canada or the EU.
But it doesn’t matter that much if a bad guy or bad government gets their hands on your password store; what matters is whether or not they can decrypt it. I’m not an infosec professional but I know some and listen to them, and both those security postures give me a good feeling. It’s not an accident that they’re pretty similar.
The actual threat isn’t so much that an adversary cracks the crypto; that’s very unlikely. It’s that they find a way to force a PM vendor to build a back door into their software to get access to keys and passwords. For that reason, it would warm my heart if either or both of Bw and 1P were to post a Warrant Canary.
But I’m going to give Bw a very slight edge. First, because of the fact that you can build and run it yourself, if you’re willing to take responsibility for operating a server with strong security requirements. (I’m not.)
The source being open potentially offers a second, and more important I think, advantage: If they were able to get a Reproducible build working, you’d have assurance that the code you can download is the one their service is running. Which reduces the attack surface. (Mind you, not to zero.) Reproducible builds are hard, but if they did that, it would make a difference to me.
On the other hand, Bw’s software development process embraces GenAI generally and Claude specifically. At this stage in the growth of those technologies, this sends a chill up my spine. To be fair, 1P’s website shouts that it’s just the thing for agentic security, whatever that means. And we don’t know anything about 1P’s internal software-dev process.
1P vs Bw: Fit and finish
1P wins this one. The problem is, do they always pop up when needed and never when they’re not? Can they fill every login field that needs filling? Does the popup show you just what you need and nothing extraneous? I’ve used both and 1P is just better.
Business issues
This one is also pretty well a saw-off. Both of them have taken substantial chunks of VC money and thus are going to come under relentless pressure to enshittify. I worry a little less about this because from what I read, there’s not much lock-in.
Personal experience too: I recently did an export of everything out of 1P and into Bw and it all Just Worked, albeit putting all my stuff into a folder named "No Folder" that I can’t figure out how to rename.
Both Bw and 1P are subscription-only, at prices that seem fair to me.
Death and recovery and pen and paper
As I was reading up on this stuff, the issue of recovering access to your PM after it had been lost came up a couple of times. Here’s a scenario where that could be really important: I die. And then my wife needs to get access to bank accounts and business emails and so on.
Somebody (I’ve lost the link) was horrified that one of the PMs suggested writing the password down on a piece of paper as a last-resort measure, but I’m here to tell you that they’re wrong. My wife has an envelope containing a piece of paper on which appear the passwords for my PM and Mac, my mobile-phone PIN, and a very small number of other secret things she might really need if I’m suddenly gone. I have no idea where she put it, but she’s really smart so I don’t worry.
You should probably do something like this too.
What will we do?
We’ve paid for a year’s worth of both Bw and 1P. At the moment, we’re leaning to 1P because it’s a little more polished. Which matters because my PM is something I use many times every day. Also they’re somewhat Canadian.
If you think we’ve missed something, please do let us know.
Long Links 24 Mar 2026, 2:00 pm
This will be the 30th Long-Links outing. I’m 100% sure that there does not live a human being who has looked at all those Links, but my logfiles say that quite a few of you, Dear Readers, at least take the time to open one occasionally. All aboard!
Sadly, more than half the Long Links, this time out, are about AI. I almost decided to bury the piece but, whatever you or I think, the subject matters. And the ones I posted are a tiny fraction of those I read (or tried to) and I think are useful and not immoral.
But, let’s put all the non-AI stuff at the front so you can stop reading partway through if you’ve just had enough of that stuff.
Not about GenAI
Paul Ford has, after a lengthy gap, started writing again at ftrain.com. Excellent! Go there any day and there’ll almost certainly be something good at the top of the page. He’s a technologist and, yeah, writes about AI sometimes, but Warp and Woof is about dogs and their people. Charming.
I think most people who aren’t ultra-wealthy now agree that inequality is currently a central problem of our society. But it would be nice to put some numbers behind that assertion. Here is a conversation between Paul Krugman, Nobel-prizewinning economist, and Gabriel Zucman, a French specialist in the subject and frequent Piketty collaborator. Now, there are quite a few paragraphs up front of talk about general macroeconomic issues and comparisons between the US and Europe, which I enjoyed reading. And then inequality; here’s Zucman: “And so everybody now understands what was long understood for centuries, very much including in the West, which is that extreme wealth is never virtual, it is always extreme power.”
CO2 densities in Parts Per Million are a good measure of how full your inhalations are of others’ exhalations. And thus of how likely you are to catch something by breathing. Especially, Covid, which everyone with a half a brain knows is not nearly over. Anyhow, A. Grieve-Smith offers Nine observations from carbon dioxide monitoring: “I’ve been checking carbon dioxide levels for over three years now, and I’ve started to see patterns.” This piece could save your life, and that’s not a metaphor.
Patrick McKenzie, who writes Bits About Money, has an icy-cool style and this Link could be a Little Less Long, but I learn interesting things every time I read one of his pieces. Fraud Investigation is Believing Your Lying Eyes launches from the Minnesota child-care fraud story, but is mostly, as the title suggests, relates the conventional wisdom (which I didn’t know) about how to go sniffing around for in-progress fraud. From which “As a fraud investigator, you are allowed and encouraged to read Facebook at work.”
Hari Kunzru has written good books and is a former London native. Harpers gave him an assignment: Walk around and write about the city, thus Another London: Excavating the disenchanted city. It’s a tour through time as much as space — London, obviously, is history-drenched — and not just politics and power either, but arts and ideas. The writing is beautiful. It’ll take a chunk out of your day but the trade-off is good.
Here’s something beautiful: The HTML Review. Now I want to publish there, but I’d have to up my writing game.
Lankum
They’re an Irish band I just discovered, courtesy of Qobuz. The music grows out of traditional Irish acoustic folk. They play old and new songs and throw in a heavy dose of snarl and drone. Some of the chords are like rotated model augmented 11ths or some such, scratchy around the edges but helped with an itch I hadn’t known I had. Terrific musicians. Here’s Hunting the Wren. I might get over-excited and fly to Ireland to see them.

Tech, but not GenAI
Sebastian Pipping is, among other things, an Open-Source software developer, with whom I’ve collaborated. His recent Learn from me! begins “Not too long ago, someone literally asked me what they "could learn from me", and that question has stuck with me since.” So he offers a few candidate lessons. What a nice idea! What could people learn from you?
Filippo Valsorda, another OSS dev, is particularly interesting because he and a few partners have apparently figured out how to make a living from their work. He recently published Turn Dependabot Off and I’m not going to offer a word of explanation because if you understand the title I guarantee you’ll be interested in the piece. (I’m terrified of Dependabot.)
It seems like every day I hear from another person who’s trying to get their personal lives off Big Tech. Me too. So… In The Verge, How to un-Big Tech your online life. And from Paris Marx, Getting off US tech: a guide. We are in the early stages of de-Googling our family life, so this stuff is super useful. I expect to see more of it.
Amazon polemics, maybe a little AI
I don’t loathe Amazon any more nor less than the rest of the Big Techs, but boy are there are a lot of people publishing diatribes against the company. Not sure I understand why. But, worth reading.
In How Amazon Dies: A Possible, Maybe Likely Future Mark Atwood predicts that the infestation of amazon.com with highly-profitable advertising is a perhaps-fatal blunder. What’s maybe more interesting is that he points out several potential Amazon alternatives that don’t suffer from that same infestation; they hadn’t occurred to me.
And from a year ago, Cory Doctorow’s The future of Amazon coders is the present of Amazon warehouse workers introduces the “shitty technology adoption curve”. I missed this piece at the time but boy, is it easy to believe.
Finally, reading Writing Crystalized Thinking At Amazon. Is AI Muddying It? angered me. While I have no remaining respect or affection for any of the Big Techs, I enjoyed my time at AWS and part of it was the writing culture. I think the Way Of The Six-pager is the best business-process innovation I witnessed in my working life. If Amazon really is slopifying it, I predict disastrous outcomes.
OK, here’s the AI stuff
My own position, just to be clear: There are going to be LLM applications in a few domains here and there, and one of them is software development, but they won’t be nearly big enough to damage earth’s climate any further, nor to prevent the bubble from popping. That said…
Let’s do the worst first: Write-Only Code lays out a genuinely frightening future. Quote: “I was maniacally insistent that any proposed change to our SDLC (software development life cycle) be evaluated first through the lens of developer velocity.” I think I’d rather not go there.
Most of us who watch the space, and have no idea where it’s going or what the future holds, are I think particularly interested in Anthropic’s Claude. If you’re one, you’ll probably enjoy What Is Claude? Anthropic Doesn’t Know, Either.
It’s probably not that GenAI is intrinsically immoral. As Karl Bode writes, The Problem With AI Is Shitty Human Beings. I covered some of the same territory last year in The Real GenAI Issue, but Bode is excellent: “…the grand vision of modern automation's benefits can never materialize if its stewards are foundationally fucking terrible human beings disinterested in the contours of empathy. If we're not talking prominently about that, we aren't really talking at all.” (Emphasis his.)
One of the things that shitty people do is lie. Like for example charismatic leaders of AI “startups” valued in the tens of billions. But then so do the less-visible, which provoked Kyle Kingsbury A.K.A. Aphyr to write Trudging Through Nonsense. It’s sad and angry but I think usefully so.
Armin Ronacher is not bursting with rage, but he is skeptical about all the right things in Some Things Just Take Time. Quote: “There’s a feeling that all the things that create friction in your life should be automated away. That human involvement should be replaced by AI-based decision-making. Because it is the friction of the process that is the problem. When in fact many times the friction, or that things just take time, is precisely the point.”
For another cool-voiced critique, here’s Rishi Baldawa: AI Mandates Manufacture Noise. While I’m not entirely a burn-it-all-with-fire GenAI foe, the “boss mandate” always struck me as dumb, and Rishi spells it out clearly and simply. It’s really good, so here are a couple of quotes: “But those not in the weeds had no way to know any of this because… well they aren’t in the weeds. So they feel compelled to solve their information gap with a policy hammer.” and “As said before, none of this is revolutionary and that’s sort of the point. AI is a ’mirror and multiplier‘. It intensifies whatever was already happening.”
That’s all
Let’s really hope the bubble bursts soonest. Because when the money goes away, so will a lot of the shitty people.
Nash Burns Saves the Day 20 Mar 2026, 2:00 pm
What happened was, soon after New Year’s, friends and colleagues in the UK and Germany started letting us know that their emails to us were bouncing. Our “textuality.com” family domain is a Google Workspace (or whatever they call it this year) for email and docs and so on. Its Web presence, including DNS, has for many years been handled by a local outfit I’ll call “CWH” for some absurdly low monthly price, and has been trouble-free.
So, what could be wrong? We investigated and discovered that Google was offering a new-and-improved MX-record option, although they emphasized that the old setup should still work. Anyhow, we installed the New Thing and it didn’t help.
So, we filed a ticket with CWH tech support and somebody got back to us pretty quick, saying they’d changed a firewall
setting that was blocking connections to Germany. I detect the scent of GDPR, but whatever.
Euro-email: Bounce, bounce.
CWH: Probably an MX-record issue, and we should wait for DNS propagation. Several days passed and
bounce, bounce, bounce.
Us: “Not DNS propagation.”
CWH: “Still could be.”
So we VPN’ed to Germany and discovered we couldn’t ping Textuality’s IP address. Smells like a firewall to me. We told CWH that.
CWH: We have made some changes to firewall settings.
EMail: bounce, bounce, bounce.
VPN+Ping: Request timeout, request timeout, request timeout.
CWH: Try traceroute?
VPN+Traceroute: 14 hops, no joy.
CWH: Your VPN settings must be wrong. Here are instructions to use Windows PC VPN correctly.
Us: Thanks but no.
CWH: Your MX records are configured incorrectly.
Us: No, they are correct per Google guidance. We sent an email beginning
“Please believe us.”
CWH: It must be DNSSEC. Check to see if your registrar implements DNSSEC.
Us: We are using your DNS servers.
CWH: Perhaps your registrar is broadcasting an old record?
Us: Our registrar doesn’t do DNSSEC.
At this point we consulted a friend who’s an expert on DNS and Email and even DNSSEC. He verified that not only could you not ping Textuality from Germany, you also couldn’t ping CWH or its name servers. Firewall firewall firewall!
CWH: “I did test the site access using a 3rd party application, and it seems to be accessible on all parts.”
Us: Look at the
output, it shows we can’t be reached from anywhere in Germany.
Also, for all the remaining messages in the email trail, we prefixed our input with bold face extra-large text reading: Systems located in Germany cannot ping Textuality.com’s IP address, nor can they ping the IP addresses of textuality.com’s designated name servers. This is the problem.
CWH: Let’s try migrating you to a different server; try pinging these hostnames.
VPN+Ping: Nope.
CWH: Are you sure it’s not your VPN settings?
Us: Are you sure it’s not your GDPR settings?
CWH: Raising your issue to Tier 3.
20 hours pass, then we get email from:
Nash Burns!
…who said “This has been fixed.” It was. Nash’s email signature was “Nash(Rajaneesh) B”. What a great name, though. Thanks, Nash.
Am we mad?
Not really. Consumer-facing tech support is hard. None of their suggestions were unreasonable. Doing GDPR correctly is hard. They’ve been just fine for years and were having a bad week. Could we expect better from any of CWH’s local competitors? Probably not.
It wasn’t funny at the time, but looking back, it kind of is.
Pure Sound Please 16 Mar 2026, 2:00 pm
This last weekend we attended a concert entitled Lenten Reflection at Vancouver’s Catholic Holy Rosary Cathedral featuring the Belle Voci vocal group and the Cantare Super Orchestram early-music band. The music was fine and it was the most beautiful sound I’ve heard in a long time. Twenty-two months, to be precise (see below). And so I get to report on good music and yell at production people.
A cathedral is a nice place for a concert!

The concert opened with just the singers, their voices drifting down from a high place behind us, a balcony or choir loft. There was no incremental accompaniment and no amplification; the music flowed from vocal cords to eardrums — not directly, of course, there was lots of reflection and reverberation introduced by the Cathedral space. The singers were polished and expressive and the sound, drifting through the vast space, beyond exquisite.
They sang a lovely piece by Byrd (1539-1623). Then the instrumentalists played a number by von Biber (1644-1704) while the singers snuck downstairs. Joined, they performed Bach’s BWV 229 and 150, then pieces by Pergolesi (1710-1736) and Steffani (1654-1728).
The Bach pieces, as usual, had more music in the music, but the others were also fun. It was a small ensemble: In the choir, five sopranos, five altos, a countertenor, four each tenors and basses. The band had five baroque violins, a baroque viola, a baroque cello, a violone (think, string bass with frets), a baroque bassoon, and a player doubling on harpsichord and organ. Thus, an ensemble quite likely not too much bigger or smaller than the ones playing this music in the 1700s, when it was new.
That sound
Once again, the sound was something special and yeah, the musicians were excellent, but for me, the key thing was the lack of amplification: vocal cord to eardrum via cathedral. It’s always seemed obvious to me that you can’t run music through a bunch of electronics and speaker mechanics without changing it; if only spatially, with the sounds coming from speaker diaphragms located somewhere away from the human musician. To my ears, there is a fragile magic in pure unamplified sound. I lack the words to describe the difference but it’s not subtle.

Does this mean that everything was perfect? No; the choir was a little bit male-heavy; some of the soprano and especially alto lines were part-hidden behind the massed male voices. Also, the bassoon was right at the front of the stage; While the playing was fine, it felt as though it were musically, not just physically “in front of” the band and singers.
Both of these could have been fixed, by telling the men to take it down a notch or having one or two fewer of them. And by moving the bassoon back to the usual woodwinds spot behind the strings. Still, these were very minor imperfections.
Oh, and the performance and sound of the bass line on that violone was absolutely awesome; clearly audible as a thing on its own while it wove all the other musical threads together.
I’ve discovered that few classical musicians share my passion for unamplification. I hear things like “I want a full sound or “The soloists need to cut through the orchestra.” Which, well, OK, but somehow people managed to accomplish those things for centuries, before amplifiers and speakers were invented.
22 months?
That’s since May of 2024 when I took in the Tedeschi-Trucks Band, whose music couldn’t be more different from anything called “Lenten Reflections”: electric not acoustic, profane not sacred. But crystal clear and perfectly balanced sound; so much better than most electric bands achieve.
My sincere thanks to the musicians and their leaders for a lovely experience. And my message to everyone co-ordinating and leading live music performances: Of course the first priority has to be the quality of the music, but think about the sound and try to be better. Better than than most performances manage, these days.
We know it’s possible.
Because Algospeak 5 Mar 2026, 2:00 pm
Recently I read Because Internet by Gretchen McCulloch and Algospeak by Adam Aleksic. The language we speak (and text) to each other is at the core of who and what we are, and the Internet is the strongest among the forces that channel and fertilize its growth. So there’s scope for plenty of books on the subject. Both books educated and entertained, one made me angry.

Because Internet (2019)
Its approach is historical and its voice fairly uninflected. It smiles and argues, but it doesn’t ROFL nor does it YELL AT YOU. The history is longer, perhaps, than most people reading this have been online (or even alive). Ms McCulloch goes back to the days of BBSes (“bulletin-board systems”) and ListServs and IRC. Some of the jargon and formulations of those days live on; you’d be surprised.
Here’s her table of contents.

The analysis is grounded in the formalisms of the author’s profession, academic linguistics. Nothing wrong with that.
Let’s look at a couple of her ideas, beginning with Chapter 1’s “Informal Writing”. A few of us, back in the late Eighties, noticed that computers in general and the then-nascent Internet in particular were driving a writing renaissance.
Before computers, a knowledge worker who had laboriously constructed essays in college quite likely wrote almost nothing for the rest of their working life. People talked face-to-face or on the phone, and dictated to secretaries. Written communication was seen as necessarily formal and disjoint from the way we spoke, or that we wrote in personal correspondence. Then, suddenly, everyone was sitting at a keyboard only seconds away from everyone else’s screen. McCulloch goes deep on this:
In the future, the era of writing between the invention of the printing press and the internet may come to be seen as an anomaly—an era when there arose a significant gap between how easy it was to be a writer versus a reader. An era when we collectively stopped paying attention to the informal, unedited side of writing and let typography become static and disembodied.
The internet didn’t create informal writing, but it did make it more common, changing some of our previously spoken interactions into near-real-time text exchanges.
From which all of this follows. It feels like a central insight. I suppose you could argue that centrality of informal text is fading in the face of short-form video. Maybe, it’s too soon to tell.
Then consider chapter 5, about emojis. Linguists obviously need to think about them because now they’re an integral part of written language. McCulloch’s insight is that they correspond almost exactly to gestures, the way we use our hands to add force to our speech. Obviously, for example, “👍”. Or when you’re talking about something completely loopy and you twirl your index finger by your ear? You meant “🤪”.
I offer the emoji story for flavor, an example of a linguist’s approach to what we’re doing to our language with our networks.
McCulloch has lots more of this stuff. I enjoyed Because Internet a lot, partly because I’m old and my memories stretch back to those BBS and IRC days and I had a front-row seat for the decades of linguistic seething and heaving. And also because I’m a Unicode geek.
Algospeak (2025)
The subtitle is “How Social Media Is Transforming the Future of Language”. OK, but… Social media is a fertile field for language evolution. Thing is, corporate social media discourse lives in the dire grip of the proprietors’ algorithms. And that’s where Adam Aleksic focuses. He treats all of them as a single opaque object, “The Algorithm”, which I think is fair because they all are designed with one goal: To maximize the effectiveness of human conversation at generating advertising revenue.
First, the Table of Contents.

Aleksic knows whereof he speaks: As “Etymology Nerd”, his aggregate following across TikTok, Instagram, and YouTube is over three million. He’s all about cool bits and pieces of linguistics, often Internet-specific usages. If I had the patience for podcasts I suppose his would be near the top of my list.
He really enjoys his work and has fun talking about some of Social Media’s more colorful linguistic extrusions; check that Table of Contents. I’m kind of old and I learned a lot about the words and emojis younger folk emit, and I think most folks, even those just out of their teens, would too. I’m on a Discord for a Major League Soccer team’s fans, and while it’s totally all-ages, I can say I am regularly less mystified than I was before I read Algospeak. For example, now I know what it means when someone tosses “💀” into a chat. Do you?
Aleksic isn’t averse to a little history himself. Looking back over the successive online-jargon volcanoes, he argues convincingly that two stand out as extra productive. First of all, the short-lived (but hot stuff at the time) Vine video platform. Second, the incel cesspool; sad but (apparently) true.
The Algorithm
Remember, it’s all about what advertisers want. And wow, do they ever want a lot of things. I’ll just touch on a few of Aleksic’s points.
First of all, they don’t want to find themselves next to downers. So if you want to talk about death or suicide or rape or racism or rage, you need to fool The Algorithm. Thus “unalive” and many other dodges. Of course, The Algorithm learns about them so you have to keep dodging. Neither side of this struggle can stay ahead for long.
Here’s another thing I didn’t know: Apparently written Chinese is particularly rich in techniques for euphemizing, making it easier for users of that language to evade, for a time, The Algorithm.
Partitioning people
Another big thing The Algorithm likes is grouping people into smaller and smaller baskets based on interests, generations, and many other criteria. This is because advertisers can aim very specific campaigns at just exactly the right cohort of people who are likely to buy what they’re selling. Here’s a quote; See how the language fills in behind advertisers’ pressure?
It doesn’t matter how much I label myself. If I’m a demisexual goblincore Gen Z Swiftie, I guarantee there are still others like me. The only thing these labels really change about me is that they make me easier to classify and market to. Ironically, true individuality may come out of a lack of labels and stories, because there’s greater freedom of expression with a blank slate. If everybody’s the “main character,” then nobody is.
Algospeak, unlike Because Internet, doesn’t limit itself to written language. One of its most compelling studies concerns the vocal techniques of podcasters and YouTubers. The finding is simple: It’s hard to build and hold an audience for your show unless you sound like MrBeast. No, really.
Anyhow, they’re both good books. Because Internet educated and entertained me. Algospeak is way more intense, intentionally more like the subject it addresses. Also it made me angry. I am a lover of human language and of its patterns of growth and mutation and simplification and complexification. Linguistics is one of the disciplines I regret not having chosen.
Aleksic makes it clear that there’s an amusing narrative about how the people living and speaking in the shade of the Algorithm can never defeat it, but they can still manage to get their messages across. But they shouldn’t have to struggle!
In fact, a few million of us have found a place to talk to each other that isn’t in The Algorithm’s shadow: Decentralized social media. Specifically the Fediverse (what people mean when they say “Mastodon”) and maybe the ATmosphere (same for “Bluesky”).
I want to see how language grows in a place where new forms arrive when they’re needed, to say new things that need to be said. Not to either serve or resist The Algorithm.
Kansas and AI 27 Feb 2026, 2:00 pm
Block announced that it’s cutting 40% of its workforce. It didn’t say it was replacing those people with GenAI. Not out loud. Jack Dorsey did say “I believe the majority of companies will reach the same conclusion and make similar structural changes.” Wall Street loved it, bidding up the share price by 24%. Which reminded me of Kansas in 2010.
The Kansas Experiment
As long as I can remember, a certain class of right-wing evangelists has preached that cutting taxes would stimulate business growth and everyone would come out ahead. There are a couple of problems with this theory. First, mainstream economists almost universally think it’s just wrong. Second, most of the people pushing it are rich and would benefit from the cuts.
Anyhow, in 2010 US Senator Sam Brownback won the race for governor of Kansas on what was then called the “Tea Party” program: Prosperity through tax cuts. Tea-party Republicans also won a large majority in the state legislature. Unsurprisingly they immediately did what they said they were going to do: Slashed a wide variety of taxes, some to zero.
The predicted prosperity failed to happen. The state government’s revenue plunged and it had to dig deep into rainy-day reserves just to keep the doors open. There were brutal cuts to policing, road repair, and schools. Also a nasty feedback loop: As the state’s fiscal position worsened, its credit rating fell and interest rates rose, leading to yet more brutal austerity measures.
Another result was that affluent Kansans made out like bandits; the cost of running the state was substantially transferred to the less financially fortunate.
In 2017, the legislature threw in their cards and repealed the tax cuts, overriding Brownback’s veto.
While this was a terrible experience for most Kansans, it is historically useful, because whenever you encounter a tax-cut nut (probably self-interestedly wealthy) you can say “But, Kansas!” Having said that, there are still plenty of those nuts, and they’ll tell you that the Kansas experiment failed because of one fine-tuning effort or another. That’s a position that’s hard to defend, though.
Sidebar: Trans oppression too
Before I move onto the AI angle, I gotta pause to acknowledge this week’s news story about the Kansas government’s vicious, brutal, and ignorant assault on trans people. To be clear, I think the shitty people who hate trans folk are aren’t necessarily the same shitty people as the shitty people who don’t want to contribute to the public good. But, something about Kansas seems to attract both flavors.
The GenAI experiment
The core value proposition of contemporary AI technology is exactly what Dorsey seems to think: Fire half your employees and profits will soar! If that’s true, the trillion dollars or so invested so far will seem like small potatoes. Since we don’t know if this will actually work, anyone who actually does it is conducting an experiment. Just like Sam Brownback did. Unsurprisingly, the investor class loves this experiment and is putting their money on it working.
To be fair, voices have been raised to argue that the tech sector is a special case: That following on feverish over-hiring during the Covid lockdown, they need to slash headcount anyhow, and are using AI as an excuse. For example John Gruber.
I personally am unconvinced, but even if they’re right, it’s irrelevant. The shareholding class won’t be able to see past that 24% payoff. So as of today, they’ll be yelling at every CEO on the planet to start pulling the mass-firing trigger. Or else.
I think I know how the experiment will turn out. Just like in Kansas, it’s not going to be fun.
Crocuses of 2026 24 Feb 2026, 2:00 pm
I’ve run early-spring pictures of these little purple guys almost every year since this blog’s birth in early 2003. Except for last year. Because we moved and the new place didn’t have any. Only now it does, and they’re (just barely) up. [Update: Up and open, too.]

Long-time followers may note that they’re pale and fragile compared to the exuberant blossoms of previous years. Not sure why, but our new place faces north and there’s this enormous White Ash tree right in front of it, so they’re not getting as much sun as at the south-facing former joint.

And also this is their first spring. We bought the bulbs and hired a professional with the right tools to jam them into the earth last autumn, between the big tree’s roots. So they really haven’t had a chance to get their own root systems going.
And finally, it really is the first day that’s bright and warm enough to get out the camera. Maybe they’ll be better in another few days. And quite likely next Spring.

This would be the place to introduce whatever metaphor this year’s blossoms, fighting their way through the leaf cover in chilly air toward the sun, fit into, but I’m not gonna.
I, like many, am not dealing very well with what I see when I look at the world in either the big or the ultra-local landscapes. The world in tough shape and its worst people are making it worse. People I love are in ugly corners and not finding help.
But you know, the flowers, in their low-key way, look great and so does the tree, still in wintersleep. Today the sun was shining on them. It’ll be warmer and nicer soon.
Metaphors can go to hell. It’s just late-winter light on pale violet petals. Enjoy the moments you have with it.

Update: Now open for business.
Open Source and GenAI? 16 Feb 2026, 2:00 pm
I’ve been puttering away on my Quamina project since 2023. In the last few weeks GenAI has intervened. Quamina + Claude, Case 1 describes a series of Claude-generated human-curated PRs, most of which I’ve now approved and merged. Quamina + Claude, Case 2 considers quamina-rs, a largely-Claude-driven port from Go to Rust. Both of these stories seem to have happy endings and negligible downsides. So empirically, I can apply LLM technology usefully to software development. But should I?
Conclusions 1: Burn it with fire?
Let me be clear: In the big GenAI picture, I’m a contra. Why? I’ll pass the mike to Baldur Bjarnason, my favorite among GenAI’s blood enemies.: “AI” is a dick move. His tl;dr is something like “GenAI is environmentally devastating and has the goal of throwing millions of knowledge workers onto the street and is being sold by the worst people and is used for horrible applications and will increase society’s already-intolerable level of inequality!” To which I reply “Yes, yes, yes, yes, and yes.”
At the end of the day, the business goal of GenAI is to boost monopolist profits by eliminating decent jobs, and damn the consequences. This is a horrifying prospect (although I’m somewhat comforted by my belief that it basically won’t work and most of the investment capital is heading straight down the toilet).
But. All that granted, there’s a plausible case, specifically in software development, for exempting LLMs from this loathing.
First of all, size. JetBrains thinks that the world has 21 million or so software developers, i.e. less than 1% of the earth’s working population. Vanishingly small in the context of the lunatic tsumani of LLM overinvestment. Training and operating the models required for a market this small is rounding error measured on the Great GenAI Overbuild scale. There aren’t enough geeks to create a detectable bump in the global carbon load.
Another odious aspect of LLMs is RLHF, “Reinforcement Learning From Human Feedback”, which relies on underpaying Third-Worlders to polish the models’ outputs. My guess is that much less is required for code-oriented LLMs. The combination of the compiler and your unit tests provide good starter guardrails. Then skilled professional intervention is required to deal with the remaining misfires, as with those Quamina PRs.
Finally, it seems making billionaires into multibillionaires is intrinsic to GenAI dreams. But software-development tools won’t do that. Once again, the market is just too small. But even if it weren’t, consider this from Steve Yegge:
For this blog post, “Claude Code” means “Claude Code and all its identical-looking competitors”, i.e. Codex, Gemini CLI, Amp, Amazon Q-developer ClI, blah blah, because that’s what they are. Clones.
(GenAI, overbuilding wherever you look.) None of these products have moats and the chance that any of them become extractive monopolies is about zilch. Nobody’s ever built a major cash-cow on developer tooling
One reason is (*gasp*) Open Source. Does anybody doubt that in the near future, there will be entirely open-source versions of what Yegge means by “Claude”?
So, if you want to condemn the use of GenAI in software development, I think you need arguments other than the fact that it’s also being promoted for societally-toxic business purposes.
I have a few. But stand by, let me push that on the stack and turn to technology for a bit.
Conclusions 2: Engineering sanity?
Question: Can LLMs even participate in quality software engineering? Baldur doesn’t think so: “The gigantic, impossible to review, pull requests. Commits that are all over the place. Tests that don’t test anything. Dependencies that import literal malware. Undergraduate-level security issues. Incredibly verbose documentation completely disconnected from reality.”
I’m not saying that these pathologies can’t or don’t happen. But in my personal experience with Quamina, they didn’t. (Mind you, it’s a hobby project.)
And when they do happen, I would assume that mature open-source projects will use a network of trust, as big operations like Linux already do. PRs that don’t have the imprimatur of someone known to be clueful will be ignored. When I saw the first of those incoming Quamina PRs, I took the time for a serious look because I knew Rob and had seen evidence that he was technically competent. If I see an incoming PR that’s nontrivial and from some rando and doesn’t pass a 120-second sanity check, it’s unlikely to get any more attention.
In fact, some essentials don’t change. If you’re not requiring that PRs be clean and test coverage be good and code reviews not be skipped and dependencies be curated, you’re going to get a lousy result whether the upstream code is coming from a human or an LLM.
But it’d be naive to think that a big change in the shape of that upstream isn’t going to affect the profession.
Bottlenecks
Speaking from personal experience, reviewing the PRs from Claude&Rob was neither faster nor slower, easier nor harder, than what I’m used to pre-GenAI. The number of my disagreements with the diffs, and the amount of arguing it took to resolve them, was also about as usual. Which creates a big problem. Because if we can generate code a whole lot faster but review doesn’t speed up, all we’ve done is moved the bottleneck in the system.
Speaking of which, Armin Ronacher offers The Final Bottleneck, from which: “When one part of the pipeline becomes dramatically faster, you need to throttle input.” Think about that.
Burnout
Meanwhile, evidence is piling up that LLM-based software development is driving developers to overwork and burnout. Here’s a cool-eyed take from Harvard Business Review. Then there’s Steve Yegge’s frantic, overly-long The AI Vampire. But my favorite, and I think a must-read, is Siddhant Khare’s AI fatigue is real and nobody talks about it. From which: “AI reduces the cost of production but increases the cost of coordination, review, and decision-making. And those costs fall entirely on the human.”
The argument we’re hearing is that GenAI makes development more efficient. And more efficient is better. Until it’s not.
I’m not sure the profession I joined last century would attract me today. And on Mastodon, @GordWait said “At our office, we are noticing a huge drop in Comp Sci co-op applications. The next generation is convinced there’s no future in programming thanks to AI hype.”
Can and should
Here’s another conundrum. Suppose we can build a whole lot more stuff, faster. Should we? I don’t know about you, but I am regularly enraged at tools that work just fine popping up “wonderful new features” modals in front of what I’m trying to get accomplished. Also at damaging UI churn, driven by product managers trying to get promoted. It’s just not obvious that speeding up software development is, in the big picture, a good thing.
And I can’t help noting that every attempt to measure the productivity boost due to GenAI has shown zero (or worse) improvement. Of course, Claude’s cheering section will point out that those studies date to 2024 which is the stone age. Maybe they’re right.
Vampires
(In which I once again go all class-reductionist.) The real problem here is late-stage capitalism, and I think is best addressed in Yegge’s AI Vampires piece, from which I quote: “…dollar-signs appear in their [employers’] eyeballs, like cartoon bosses. I know that look. There’s no reasoning with the dollar-eyeball stare.” Yeah.
Thus the ancient question: cui bono? Assuming GenAI genuinely boosts productivity, who gets the benefits? Because the ownership class sure doesn’t think they should go to their newly-more-efficient employees.
But, what do I know?
I know that you gotta have test coverage or your software is an unmaintainable tangle of festering tech debt. I know you gotta have code review or your quality is on inexorable downhill drift. I don’t know how to build LLMs into a sane, sustainable software engineering culture. Nor what to do about capitalism’s AI Vampires.
And I absolutely do not believe the wild-eyed claims of 10× productivity gains, assuming we demand (as we should) that they’re sustainable at scale.
So, would I advise executives to tell software engineering shops to discard their culture in favor of vibe coding in the expectation of monstrous productivity wins? Nope. Vibe engineering, maybe. Centaurs, not reverse centaurs? Indeed.
But would I say “Stay away, don’t even look”? Nope. I’d probably suggest pointing the LLM at well-delimited non-strategic issues and optimizations, and emphasize no shortcuts on reviewing or CI/CD standards.
Also note that the GenAI apostles are at one in saying that this year’s tools are so much better than last year’s, and next year’s are guaranteed to be qualitatively still better! So why would you rush in and risk getting locked into soon-to-be-outmoded tooling?
Rob Sayre wrote “I would never bother to type out these patches by hand. But I read them all.” I probably wouldn’t have either and I read them too. And now Quamina is roughly twice as fast. Which is to say, I got good results on a hobby project. That’s not nothing.
But, also not conclusive. Once the AI bubble pops and we’ve recovered from the systemic damage, I think there’ll probably be a place for open-source LLM automation in developer toolkits.
But maybe not. Wouldn’t surprise me much, either way.
Quamina + Claude, Case 2 14 Feb 2026, 2:00 pm
Last time out I described a bunch of incremental-improvement Quamina PRs from a colleague working with Claude Opus. Today I want to talk about Rishi Baldawa’s quamina-rs, a Claude-based port of Quamina from Go to Rust. The next post is about where I stand on GenAI and code.
Anybody who cares about this kind of thing will appreciate Rishi’s write-ups, starting with The Agents Kept Going (also see Scaffolding for Agent Velocity). He doesn’t just say what he did, he draws lessons; good ones, I think.
Background
Rishi and I worked together at AWS, can’t remember the details, but after I left he took over what we called Ruler, now known as aws/event-ruler, Quamina’s ancestor. At the time I left it had been adopted by quite a number of AWS and Amazon services and various instances were processing, in aggregate, a remarkable number of millions of events per second. So he knows the territory.
As for quamina-rs, go read his blogs. I’ve got little to add, but here are a couple of juicy quotes: “…at some point while I was mindlessly kicking off these sessions, the agents started picking up open issues from the Go version and implementing them on their own.“ Also, “And I think that’s the thing worth saying plainly. It’s human to care. Agents don’t care. Automation doesn’t care. They need to be told what to care about, and even then they’ll misbehave the moment you look away…”
Both these stories ended with useful results. So empirically, you can get useful results by applying GenAI to the process of code construction.
Yay. I guess. But there are a lot of smart people who think this whole LLM-fueled coding direction is irremediably toxic. I’m not sure they’re wrong.
Quamina + Claude, Case 1 6 Feb 2026, 2:00 pm
With 47 years of coding under my belt, and still a fascination for the new shiny, obviously I’m interested what role (if any) GenAI is going to play in the future of software. But not interested enough to actually acquire the necessary skills and try it out myself. Someday, someday. Didn’t matter; two other people went ahead without asking and applied Claude to my current code playground, Quamina. Here’s the first story. I’m going to go ahead and share it even though it will make people mad at me.
Why share?
Because our profession’s debate on this topic is simultaneously ridiculous and toxic. No meaningful dialogue seems possible between the Gas Town-and-Moltbook faction and the “AI” is a dick move camp. So, I’m not going to join in today. This is pure anecdata: What happened when Rob applied Claude to Quamina. I’m going to avoid rhetoric (in the linguistic sense, language designed to convince) and especially polemic (language designed to attack). I promise to have conclusions before too long, just not today.
What happened was…
There’s this guy Rob Sayre, I’ve known him for many years, even been in the same room once or twice, in the context of IETF work. I’ve never previously collaborated on code with him. Starting in mid-January, he’s sent a steady flow of PRs, most of which I eventually accept and merge.
The net result is that Quamina is now roughly twice as fast on several benchmarks designed to measure typical tasks.
Technical details
The details of what Quamina is and does are in the
README. For this discussion, let’s ignore everything
except to say that it’s a Go library and consider its two most important APIs. AddPattern() adds a Pattern (literal or
regexp) to an instance, and
MatchesForEvent considers a JSON blob and reports back which Patterns it matched. It’s really fast and the
relationship is pleasingly weak between the number of Patterns that have been added and the matching speed.
Quamina is based around finite automata (both deterministic and nondeterministic) and the rest of this technical-details section will throw around NFA and DFA jargon, sorry about that.
For code like this that is neither I/O-bound nor UI-centric, performance is really all about choosing the right
algorithms. Once you’ve done that, it’s mostly about memory management. Obviously in Quamina, the AddPattern call
needs to allocate memory to hold the finite automata. But I’d like it if the MatchesForEvent didn’t.
Go’s only built-in data structures are “map” i.e. hash table, and “slice” i.e. appendable array. (For refugees from Java, with its dozens of flavors of lists and hashes, this is initially shocking, but most Go fans come to the conclusion that Go is right and Java is wrong.) In really well-optimized code, you’d like to see all the time spent either in your own logic or in appending to slices and updating maps.
In less-well-optimized code, the profiler will show you spending horrifying amounts of time in runtime routines whose names include “malloc”, and in the garbage collector. Now, both maps and slices grow automatically as needed, which is nice, except when you’re trying to minimize allocation. It turns out that slices have a capacity, and as long as the number of things you append is less than the capacity, you won’t allocate, which is good. Thus, there are two standard tricks in the inventory of 100% of people who’ve optimized Go code:
When you make a new slice, give it enough capacity to hold everything you’re going to be adding to it. Yes, this can be hard because you’re probably using it to store input data of unpredictable size, thus…
After you’ve made a new slice, keep it around, clear it after each input record, and its capacity will naturally grow until it gets to be big enough that it fits all the rest of the records, then you’ll never allocate again.
Those PRs
Background: Quamina is equipped with what I think is a pretty good unit-test suite, and multiple benchmarks.
I started getting Rob’s PRs and initially, 100% of them were finding ways along both of those well-trodden map-and-slice paths, in places where I hadn’t noticed the opportunity. They were decent PRs, well-commented, sensible code, no loss of test coverage. After I asked to see benchmark runs to prove the gains weren’t just theoretical, they started including benchmark runs. I’ve found a few things to push back on but Rob and I had no problem sorting those out.
At the end of the day I had no qualms about merging them, but I did find myself wondering how they were built. So I asked.
Workflow
Rob had told me right away on the first one that these were substantially Claude-generated. I asked him for his workflow and part of what he said was “I might say ‘let's do some profiles of memory and CPU on this benchmark, on main and on this branch.’ It will come up with good and bad ideas, then I pick them.”
Also: “What might be counter-intuitive is that I can context switch really quickly with it. So, you leave a comment, and I just tell Claude to fix that, because you are correct. Sometimes I go in and hand edit, but usually it gets close or perfect (what they call a "one-shot"). But I just have the conversation open, so I just pick up where we left off.”
Here’s a sample of Claude talking to Rob. You may have to enlarge it.

Not just the same-old
Then I got a surprise, because Claude and Rob spotted two pretty big improvements that aren’t on the standard list. First: To traverse an NFA, for each state you have to compute its “epsilon closure”, the set of other states you can get to transitively following epsilon transitions. I had already built a cache so that as you computed them, they got remembered. C&R pointed out “Epsilon closures are a property of the automaton structure, not the input data. Once a pattern is added and the NFA is built, the epsilon closure for any given state is fixed and never changes.” So you might as well compute it and save it when you build the NFA.
This is even better than it sounds, because (for good reasons following from Quamina’s concurrency model) my closure caches were per-thread, while the new epsilon closures were global, stored just once for all the threads. Not bad, and not trivial.
Second, when you’re computing those closures, you have to memo-ize the key functions to avoid getting caught in NFA loops.
I’d done this with a set, which in Go you implement as map[whatever]bool. R&C figured out that if you gave each
state a “closure generation” integer field and maintained a global closure-generation value, you could dodge the necessity for the
set at the cost of one integer per state. The benchmarks proved it worked.
As I wrote this piece, another PR arrived with a stimulating title: “kaizen: allocation-free on the matching path”.
Kaizen?
It’s the idea that you make things substantially better by successively introducing small improvements. We try to use the term to tag Quamina PRs that change no semantics but just make performance better or more reliable or whatever.
But GenAI is bad!?!
Yes, so they say. Go re-read that dick-move polemic.
But, I’m going to leave this little case study conclusion-free for a bit because there are two follow-up pieces. Next, the story of quamina-rs, a Claude-drive port of Quamina to Rust. Finally, Open Source and GenAI?.
Long Links 3 Feb 2026, 2:00 pm
Welcome to the first Long Links of this so-far-pretty-lousy 2026. I can’t imagine that anyone will have time to take in all of these, but there’s a good chance one or two might brighten your day.
Unclassified
Thomas Piketty is always right. For example, Europe, a social-democratic power.
Lying is wrong. Conservatives do it all the time. To be fair, that piece is about the capital-C flavor, as in the Canadian Tories. But still.
Clothing is open-source: “If you slice the different parts off with a seamripper, lay them all down, trace them on new fabric, cut them out, and stitch them back together, you can effectively clone and fork garments.” From Devine Lu Linvega.
The Universe is weird. The Webb telescope keeps showing astronomers things that shouldn’t be there. For example, An X-ray-emitting protocluster at z ≈ 5.7 reveals rapid structure growth; ignore the title and read the Abstract and Main sections. With pretty pictures!
Music
One time in Vegas, I was giving a speech, something about cloud computing, and was surprised to find the venue an ornate velvet-lined theater. I found out from the staff, and then relayed to the audience, that the last human before me to stand on this stage in front of an audience had been Willie Nelson. I was tempted to fall to my knees and kiss the boards. How Willie Nelson Sees America, from The New Yorker, is subtitled “On the road with the musician, his band, and his family” but it ends up being the kernel of a good biography of an interesting person. Bonus link; on YouTube, Willie Nelson - Teatro, featuring Daniel Lanois & Emmylou Harris, Directed by Wim Wenders. Strong stuff.
Speaking of recorded music, check out Why listening parties are everywhere right now. Huh? They are? As a deranged audiophile, sounds like my kind of thing. I’d go.
Somewhere to put worker bees
When I was working at AWS in downtown Vancouver back starting in 2015, a lot of our junior engineers lived in these teeny-tiny little one-room-tbh apartments. It worked out pretty well for them, they were affordable and an easy walk from the office and these people hadn’t built up enough of a life to need much more room. For a while this trend of so-called-“studio” flats was the new hotness in Vancouver and I guess around quite a bit of the developed world. Us older types with families would look at the condo market and tell each other “this is stupid”.
We were right. The bottom is falling out and they’re sitting empty in their thousands. And not just the teeniest either, the whole condo business is in the toilet. It didn’t help that for a few years all the prices went up every year (until they didn’t) and you could make serious money flipping unbuilt condos, so lots of people did (until they didn’t).
Anyhow, here’s a nice write-up on the subject: ‘Somewhere to put worker bees’: Why Canada's micro-condos are losing their appeal. (From the BBC, huh?)
AI AI AI
Sorry, I can’t not relay pro- and anti-GenAI posts, because that conversation is affecting all our lives just now. I am actually getting ready to decloak my own conclusions, but for the moment I’m just sharing essays on the subject that strike me as well-written and enjoyable for their own sake. Thus ‘AI' is a dick move, redux from Baldur Bjarnason. Boy, is he mad.
Sam Ruby has been doing some extremely weird shit, running Rails in the browser, as in without even a network connection or a Ruby runtime. Yes, AI was involved in the construction.
Software
There’s this programming language called Ivy that is in the APL lineage; that acronym will leave young’uns blank but a few greying eyebrows will have been raised. Anyhow, Implementing the transcendental functions in Ivy is delightfully geeky, diving deep with no awkwardness. By no less than Rob Pike.
Check out Mike Swanson’s Backseat Software. That’s “backseat” as in “backseat driver”, which today’s commercial software has now, annoyingly, become. This piece doesn’t make any points that I haven’t heard (or made myself) elsewhere, but it pulls a lot of the important ones together in a well-written and compelling package. Recommended.
Old Googler Harry Glaser reacts with horror to the introduction of advertising by OpenAI, and makes gloomy predictions about how it will evolve. His predictions are obviously correct.
The title says it: Discovering a Digital Photo Editing Workflow Beyond Adobe. It’d be a tough transition for me, but the relationship with Adobe gets harder and harder to justify.
Indigenous reconciliation
Khelsilem is one of the loudest and clearest voices coming out of the Squamish nation, one of the larger and better-organized Indigenous communities around here.
There has been a steady drumbeat of Indigenous litigation going on for decades as a consequence of the fact that the British colonialists who seized the territory in what we now call British Columbia didn’t bother to sign treaties with the people who were already there, they just assumed ownership. The Indigenous people have been winning a lot of court cases, which makes people nervous.
Anyhow, Khelsilem’s The Real Source of Canada's Reconciliation Panic covers the ground. I’m pretty sure British Columbians should read this, and suspect that anyone in a jurisdiction undergoing similar processes should too.
Resonant computing, Black and Blue sky
There’s this thing called the Resonant Computing Manifesto, whose authors and signatories include names you’d probably recognize. Not mine; the first of its Five Principles begins with “In the era of AI…” Also, it is entirely oblivious to the force driving the enshittification of social-media platforms: Monopoly ownership and the pathologies of late-stage capitalism.
Having said that, the vision it paints is attractive. And having said that, it’s now featured on the flags waved by the proponents of ATProto, which is to say Bluesky. See Mike Masnick’s ATproto: The Enshittification Killswitch That Enables Resonant Computing (Mike is on Bluesky Corp’s Board). That piece is OK but, in the comments, Masnick quickly gets snotty about the Fediverse and Mastodon, in a way that I find really off-putting. And once again, says nothing about the underlying economic realities that poison today’s platforms.
I want to like Bluesky, but I’m just too paranoid and cynical about money. It is entirely unclear who is funding the people and infrastructure behind Bluesky, which matters, because if Bluesky Corp goes belly-up, so does the allegedly-decentralized service.
On the other hand, Blacksky is interesting. They are trying to prove that ATProto really can be made decentralized in fact not just in theory. Their ideas and their people are stimulating, and their finances are transparent. I’ll be moving my ATProto presence to Blacksky when I get some cycles and the process has become a little more automated.
Good crypto
The cryptography community is working hard on the problem of what happens should quantum computers ever become real products as opposed to over-invested fever dreams. Because if they ever work, they can probably crack the algorithms that we’ve been using to provide basic Web privacy.
The problem is technically hard — there are good solutions though — and also politically fraught, because maybe the designers or standards orgs are corrupt or incompetent. It’s reasonable to worry about this stuff and people do. They probably don’t need to: Sophie Schmieg dives deep in ML-KEM Mythbusting.
Books
Here’s one of the most heartwarming things I’ve read in months: A Community-Curated Nancy Drew Collection. Reminder: The Internet can still be great.
John Lanchester’s For Every Winner a Loser, ostensibly a review of two books about famous financiers, is in fact an extended howl of (extremely instructive) rage against the financialization of everything and the unrelenting increase in inequality. What we need to do is to take the ill-gotten gains away from these people and put it to a use — any use — that improves human lives.
I talk a lot about late-stage capitalism. But Sven Beckert published a 1,300-page monster entitled Capitalism; the link is to a NYT review and makes me want to read it..
Charlie Stross, the sci-fi author, likes webtoons and recommends a bunch. Be careful, do not follow those links if you’re already short of time. Semi- or fully-retired? Go ahead!
I have history with dictionaries. For several years of my life in the late Eighties, I was the research project manager for the New Oxford English Dictionary project at the University of Waterloo. Dictionaries are a fascinating topic and, for much of the history of the publishing industry, were big money-makers; they dominate any short list of the biggest-selling books in history. Then came the Internet.
Anyhow, Louis Menand’s Is the Dictionary Done For? starts with a review of a book by Stefan Fatsis entitled Unabridged: The Thrill of (and Threat to) the Modern Dictionary which I haven’t read and probably won’t, but oh boy, Menand’s piece is big and rich and polished and just a fantastic read. If, that is, you care about words and languages. I understand there are those who don’t, which is weird. I’ll close with a quote from Menand:
“The dictionary projects permanence,” Fatsis concludes, “but the language is Jell-O, slippery and mutable and forever collapsing on itself.” He’s right, of course. Language is our fishbowl. We created it and now we’re forever trapped inside it.
Page processed in 0.653 seconds.
Powered by SimplePie 1.3.1, Build 20131001021811. Run the SimplePie Compatibility Test. SimplePie is © 2004–2026, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.