Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
AI coding token costs are on track to rival human payroll | InfoWorld
Technology insight for the enterpriseAI coding token costs are on track to rival human payroll 24 Jun 2026, 7:48 pm
Enterprises may soon be paying as much for their developers’ AI token usage as they do for their salaries.
According to Gartner, these costs will meet, or even exceed, the typical software engineer’s monthly salary within the next two years.
This is not only because developers are increasingly adopting generative AI and agentic tools, it reflects a trend toward consumption-based licensing models as vendors balance infrastructure investments with profitability. Rather than the flat per-seat SaaS model of the past, enterprises now pay for developer token use as well.
Gartner senior principal analyst Nitish Tyagi explained that it’s important to note that Gartner’s prediction is based on a global average salary of $2,000 per month; it doesn’t mean AI token usage will exceed all salaries. For instance, in the US, yearly pay rates can be six digits or more.
However, that kind of spend is not out of the realm of possibility, Tyagi emphasized. “I have heard scary numbers like ‘My developer consumed $20K last month,’ or ‘A business user consumed $32K’.”
If these amounts sound shocking, that’s the point. “The goal is to alarm the industry about the impact of token cost if it is not governed and controlled,” he said.
Lack of visibility, immature oversight
Enterprises are quickly moving from experimentation to scaled deployment of AI coding agents, but many still underestimate token costs, Tyagi noted.
This is because cost structures for software engineering workloads are “highly variable,” he pointed out, and there isn’t a lot of transparency into how token consumption is calculated and billed.
AI coding vendors have yet to deliver “mature, built-in cost optimization capabilities,” Tyagi said, and prices will likely only continue to rise as vendors further build out their models while at the same time trying to remain profitable.
Thus, enterprises struggle to forecast and control costs, and, because AI is moving so fast, many organizations lack the “maturity and frameworks” to determine ROI, he noted. Agent-driven workflows are difficult to govern, context windows become bloated, budgets are wiped out earlier than anticipated, and token spend becomes hard to justify.
Added to this, light users such as non-developers will increase their usage as they become more familiar with, and even reliant on, AI tools, driving up token consumption and spend even more.
Tyagi said that, while AI is incredibly valuable, he sees no “direct relationship” between the number of tokens developers consume and their productivity gains. Rather, applying context engineering principles to optimize or reduce token consumption increases quality.
“Tokenmaxxing is not directly related to higher productivity gains,” Tyagi said, “but optimizing token consumption is.”
Still, this in no way means that organizations should move away from AI coding agents, he emphasized. Optimizing token consumption simply means spending only as much as needed without compromising the quality and value brought by AI.
“Without a governed engineering operating model, costs can escalate faster than the productivity gains these tools are designed to deliver,” Tyagi said.
How enterprises can control token usage
The traditional ‘lines-of-code-written’ productivity metric no longer applies when AI can almost instantaneously produce entire Python libraries. Rather, value should be measured in quality, speed, and customer satisfaction metrics, Tyagi said.
For instance: How quickly are developers able to release important features? How much time is reduced between app development and feedback from business, product, and development teams? Shipping features quickly while maintaining quality can create competitive advantage and improve user and customer experience, he said.
Gartner also advises establishing strong governance and cost controls. For instance, introduce token thresholds, automate usage monitoring, and create explicit escalation policies.
“Embedding these controls into engineering workflows ensures consistency and prevents uncontrolled cost growth,” the firm notes.
In addition, enterprises should create a “use case driven” decision framework. This means clearly defining when AI coding agents should be used, and their appropriate levels of autonomy given certain tasks. Further, classify those tasks into three execution models: ‘developer‑led,’ ‘developer‑with‑agent’, and ‘fully agent‑led.’
Enterprises should also select models based on task complexity. Break work into smaller tasks that can be performed by smaller models, “with escalation only when complexity demands it,” Gartner advises. Engineering teams should route workflows deliberately, directing simpler, high-frequency tasks to smaller models and using frontier models only for complex and high-value work.
Another cost saving tactic is mandating specific context engineering practices, the firm says. Developers should be trained to optimize the context they input to AI, including only the information that’s relevant, summarizing that content as much as possible, and eliminating unnecessary data.
Further, teams should embed token usage reviews into development cycles. Regular review of high token consuming workflows can help identify inefficiencies, refine practices, and support collaboration, Gartner says.
Tyagi noted that developers tend to optimize for speed and convenience rather than cost efficiency, so token discipline cannot be achieved through developer choice alone.
His advice for leaders: Do not treat escalating AI coding costs as a reason to move away from AI, or to shift to open generative AI models for everything. “The goal is always to optimize costs without compromising the value.”
Start small, and focus on context engineering first, he said. Assess your current software engineering maturity and select the appropriate agent autonomy. AI assistive development can provide up to 20% productivity gains, “which is not a bad number.”
For developers, he advises: “Target context engineering as one of the most important skills for yourself. This is not only going to help your employer, but also your career.”
This article originally appeared on CIO.com.
{kind=link}
Anthropic’s Claude Tag aims to turn workplace AI from a personal assistant into a teammate 24 Jun 2026, 12:57 pm
Claude Tag is Anthropic’s latest attempt at getting Claude out of your DMs and into your team’s Slack channels.
AI assistants are increasingly showing up in the workplace to perform research, coding, writing, and analysis, but the results of those interactions typically remains tied to individual conversations rather than being shared across projects and teams.
That limitation is what Anthropic is addressing with Claude Tag, a new Slack channel-based experience for its Enterprise and Team customers, designed to give them a shared AI collaborator that retains context across conversations and participates in work with multiple employees.
Tag will replace Anthropic’s previous attempt at this, Claude in Slack, would only interact with one person (although it’s responses were visible to all in a channel) and its context was limited to the last 20 messages in a channel.
Claude Tag has a much larger context and can be asked to complete tasks on its own, returning with results and a log of how it completed the task for review. It can also schedule follow-up work for itself, enabling projects to continue over hours or days without constant prompting, Anthropic said.
Tag also has an “ambient” mode: when this is enabled, it proactively surfaces relevant information from other channels and connected tools, notifying teams about updates that may be important, and following up on unresolved discussions or tasks, the company said.
Shared context could unlock productivity gains
These features could act as an immediate productivity enhancer for enterprises by reducing coordination overhead and improving collaboration across engineering, developer, and business teams, analysts said.
The biggest benefit for enterprises is the reduction in time spent finding information and rebuilding context across AI interactions, according to Pareekh Jain, principal analyst at Pareekh Consulting. “Because Claude remembers what’s been said across channels, it acts like shared team memory, so no one has to repeat context or hold endless catch-up meetings.”
That reduction in coordination overhead, according to Amit Jena, AI development manager at IT consulting firm Kanerika, could deliver productivity gains that go well beyond the incremental improvements associated with traditional AI assistants.
“For engineering teams, Claude Tag will help reduce time spent on debugging through fragmented Slack discussions, summarizing long incident threads, pulling context across repos, tickets, and logs, and documenting decisions after the fact,” Jena said, while for business teams, “It could enable faster decision-making from thread summaries while reducing follow-ups in cross-functional work.”
Sohail Dev Majumdar, principal analyst at Gartner, though, sees greater benefits than mere productivity gains, particularly for CIOs and other technology leaders.
CIOs may need new governance and ROI metrics
The new offering reflects growing demand among enterprises for AI systems that can work across teams, retain organizational context, participate more actively in day-to-day workflows, and generate more measurable return on investment, he said.
On that last point, though, he warned that CIOs will need to change how they measure ROI for collaborative AI systems compared to traditional AI assistants: “ROI measurement must go beyond license counts, focusing on both hard metrics like time savings and error reduction; and soft metrics, such as employee satisfaction and innovation.”
Jena said CIOs will also need to reconsider auditability and governance around Tag, as it can access context, data, and tools outside individual user boundaries and influence downstream systems.
“CIOs should rethink who can assign tasks to AI agents, what data a channel-level agent can access, how AI-generated outputs are reviewed and approved, how long conversational memory should persist, and. how compliance logs map to AI actions,” Jena said.
With this in mind, Anthropic is shipping controls that will enable system administrators to filter access to data, tools, and Slack channels along with spending limits. These controls, the company said, will also enable administrators to create separate Claude instances for different teams, with each instance limited to the channels and information assigned to it.
Teamwork incentivizes
To encourage adoption, Anthropic is offering a one-time pool of launch credits to eligible organizations, enabling employees to experiment with the service before it begins consuming their regular usage allocation. Eligible Claude Enterprise customers will receive $25,000 in promotional credits, while qualifying Claude Team customers with at least 10 paid seats will receive credits worth $2,500, the company said.
The credits can be used only for Claude Tag interactions in Slack channels and will remain valid through September 1, 2026.
Tag will replace Claude in Slack on August 3, 2026 — or administrators can opt in early in the next 30 days.
This article first appeared on Computerworld.
{kind=link}
Using Visual Studio Code’s ‘air-gapped’ AI model mode 24 Jun 2026, 4:00 am
Microsoft has been pushing hard to make Visual Studio Code a major way to consume its AI services, mostly in the form of GitHub Copilot. GitHub Copilot’s deep integration with VS Code brings many conveniences — inline autocomplete, for instance — but it’s frustrating for those, like me, who would rather use another model provider, or even a locally hosted LLM, for those functions.
Visual Studio Code 1.122 introduced a new feature, “Use BYOK [Bring Your Own Key] without a GitHub sign-in,” that allows you to “use chat, tools, and MCP servers in air-gapped or restricted environments where GitHub sign-in isn’t possible.” More importantly, it “enables fully offline workflows with local models like Ollama.”
In other words, you can now use locally hosted LLMs for chat, tools, and Model Context Protocol servers inside Visual Studio Code. The one thing you still can’t do is use a local LLM for inline and next-edit suggestions — at least, not without additional tooling.
Choosing a model for BYOK mode
If you want to use a local LLM with VS Code’s bring-your-own-model system, the first thing you need is a way to host the model. VS Code lacks a model-hosting mechanism of its own, although it’s conceivable that a VS Code extension may offer something like that in the future. That said, hosting models is complicated enough that a dedicated app is really needed for the job.
One easy way to host models is via a product like LM Studio, a convenient GUI for standing up, serving, and managing LLMs on one’s own hardware. The model host does not have to be the same system you run VS Code on, either. It can be on a server box you control, or on a cloud instance.
The choice of model is also important. Many models are powerful but won’t run well on commodity hardware because they’re simply too big. A good rule of thumb is to choose a model that fits into existing VRAM, along with the memory needed for a sizable token context (the more, the better). Also, the model should be suited to coding and development work. Some models in this vein that fit comfortably into 8GB VRAM include:
- Gemma4 (effective 2 billion parameters version)
- Qwen3.5 9B
- Codestral 22B v.0.1 (proprietary license)
Setting up BYOK mode in VS Code
Once you have a model up and running, you can integrate it with Visual Studio Code. If you’ve disabled VS Code’s AI features, you will need to turn them on. Make sure the setting chat.disableAIFeatures is turned off. You can find it in Settings | Chat | Miscellaneous.
Third-party language models are managed through Visual Studio Code’s language model list. Press Ctrl-Shift-P and type Manage Language Models to open the list of existing language models.
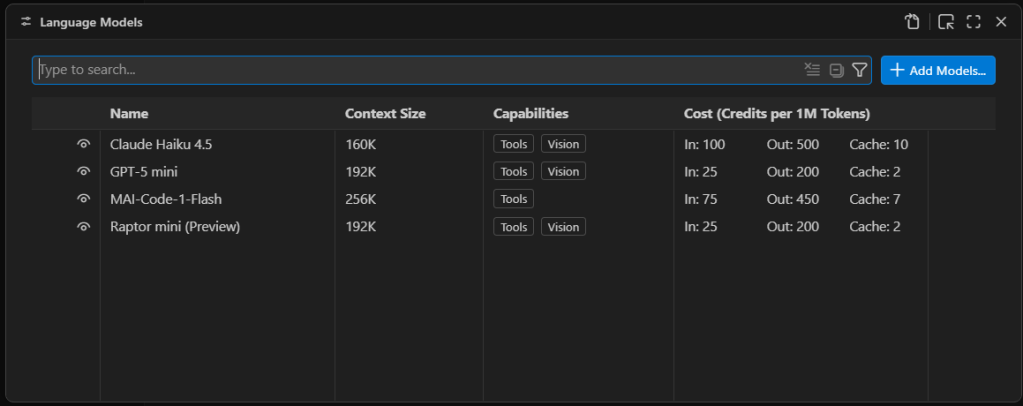
Managing VS Code’s AI language model list. The models available by default are only models available as external APIs, not models that run locally.
Foundry
First you will see a list of the built-in models, which are all externally hosted. To add a new model, select Add Models at the top right and select Custom Endpoint.
You’ll then get a series of prompts:
- Group Name: This is “Custom Endpoint” by default, but you can choose any name you want. The name is strictly for organizing the model list and doesn’t affect things like model recognition or connectivity.
- API Key: If you’ve configured LM Studio to use an API key for serving models, provide it here. If you’re hosting the model locally and you haven’t explicitly set up API keys, you can leave this blank.
- API Type: The options here are
Chat Completions,Responses, andMessages. Most of the time you’ll want to useResponses, as it’s the most general-purpose option of the three.
Once you finish providing those answers, you’ll be dropped into a modal editor for a JSON file that holds the details about the endpoint you’re configuring.
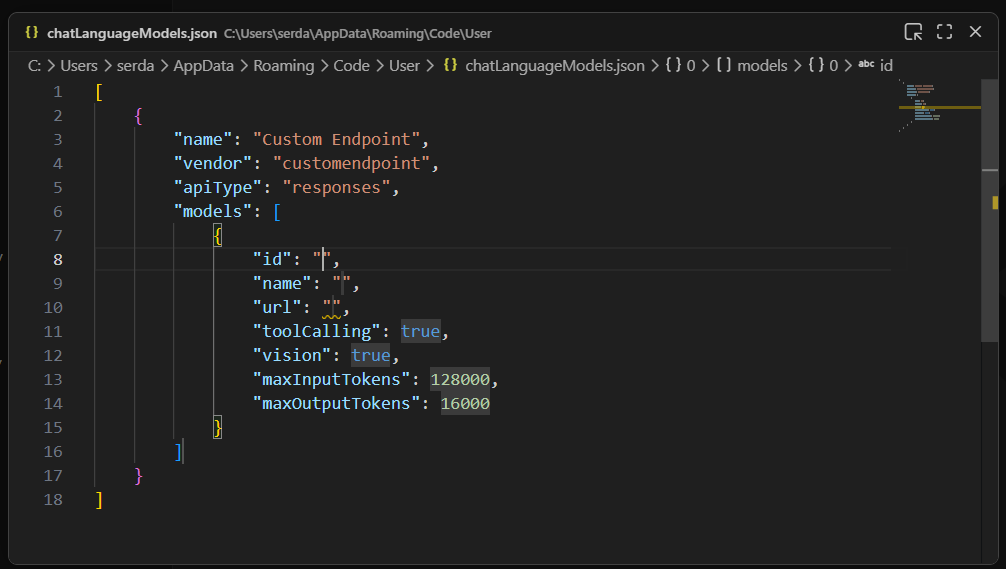
A newly created custom endpoint for a locally hosted model. The ID, name, and URL still need to be defined for this model to be useful.
Foundry
You’ll need to provide a few more details by typing them into the labeled fields:
id: A text field that uniquely identifies this particular entry. The choice of ID is pretty much arbitrary; if you’re using only a single model, the ID could be the model name.name: The name of the model that is used to identify it on the model server. In LM Studio, you can get this name by clicking onMy Modelsin the main interface, then selecting the three-dot icon for the model in question and clickingCopy Default Identifier. For Qwen 2.5, for instance,namemight be something likeqwen2.5-coder-7b-instruct.url: The URL to the server’s endpoint. On LM Studio, this defaults to something likehttp://127.0.0.1:1234/v1. The/v1at the end is important because that endpoint is used for autodiscovery of models and their capabilities.
The other fields generally don’t need editing. Most models have tool calling functionality. If you know for a fact that the model you’re using doesn’t have vision support, then set vision to false.
Once you have these fields filled in, you can close the modal editor to save the changes. If you reload the Manage Language Models page, you’ll now see your new endpoint:
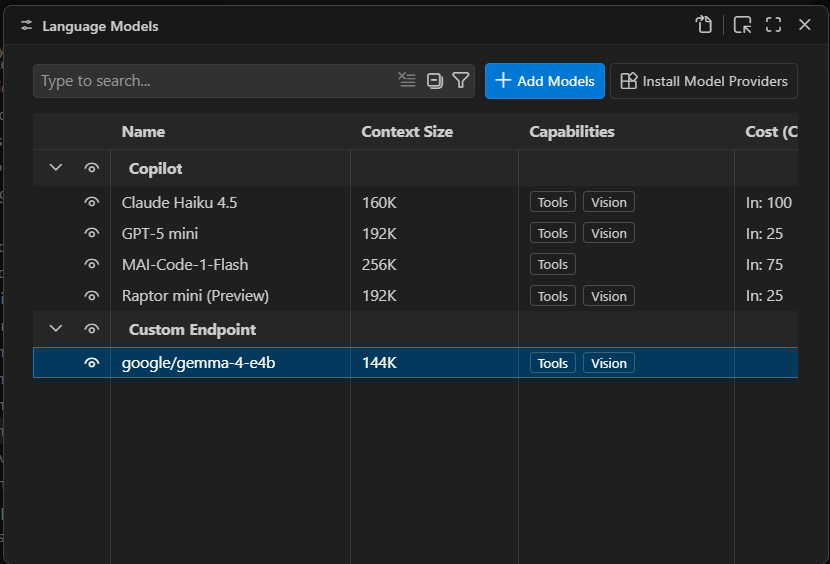
A newly created local endpoint. The choice of name and group is arbitrary. “Custom Endpoint” is the default name for a newly created group of endpoints.
Foundry
You should now be able to launch the chat window and use the defined model for conversation and utilities:
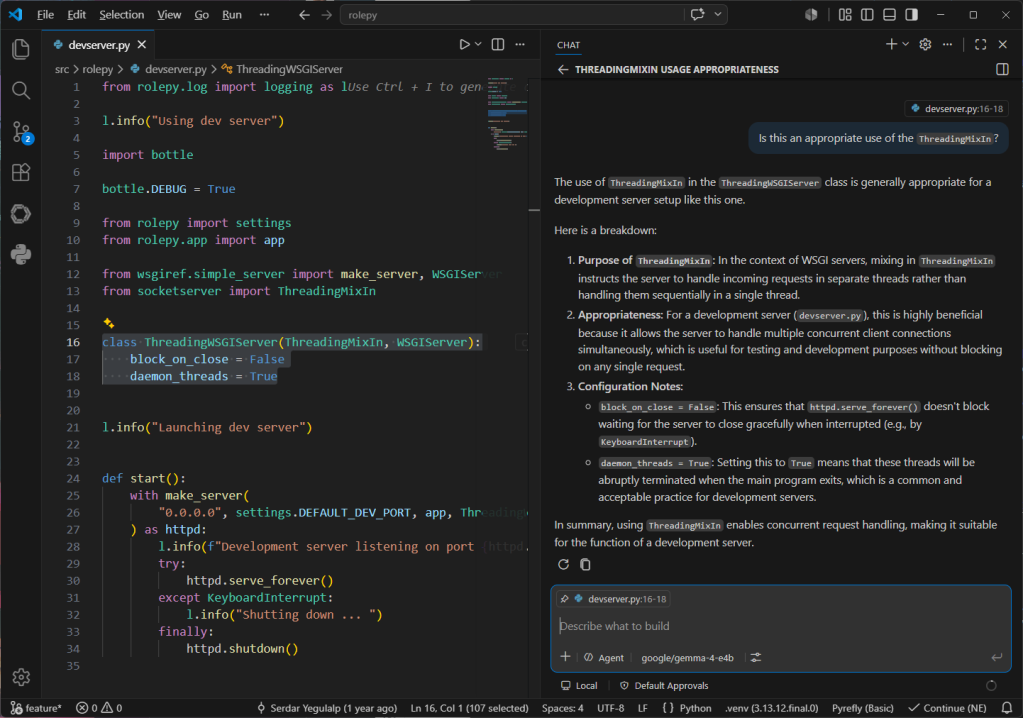
Conversing with the local model using VS Code’s chat window. Note the selected code block in the left pane that is being used as the context for the conversation.
Foundry
One current, and major, limitation of Visual Studio Code’s BYOK functionality is that it only works for chat and utility tasks. It doesn’t allow you to use a local model for inline suggestions or code completions. The only way to take advantage of local models for expanded functionality with VS Code is to use a third-party tool like Continue.
It isn’t clear if Microsoft will eventually lift this restriction. GitHub Copilot integration in VS Code is a large part of how Copilot as a service reaches its target audience. For the time being, you can certainly use third-party and local models for a significant part of your AI-assisted development work in VS Code, and you can close the functionality gap with additional tooling.
{kind=link}
Open source grapples with agentic coding 24 Jun 2026, 4:00 am
Unless you’ve been living under an old woodpile in your backyard, you have certainly seen how agentic coding is rocking the software development world. Things are happening fast and furious, and keeping up is practically a full-time job.
The latest area that is catching the attention of developers is how agentic coding is affecting the open source community. The open source movement has been defending the rights of folks to use, change, and contribute to software for many years. And of course, agentic coding is starting to become part of that process.
On the one hand, maintainers of open source projects rightfully are frustrated as they become overwhelmed with pull requests of dubious quality and usefulness being submitted by coding agents. On the other hand, as David Heinemeier Hansson notes, maintainers are starting to get a little snooty about accepting AI-written code, viewing it as somehow not worthy of being included. Some organizations have explicitly banned AI-generated submissions.
I get that they don’t want AI slop overwhelming their input queues. But I think it is a huge mistake to ban AI-written code outright.
Whose code?
Before I dig deeper into that notion, it’s important to look at another issue that arises from all of this: Who actually owns the code that AI writes?
Copyright requires that a human produce the thing being copyrighted. If you prompt Claude Code with “Write me a CMS system” and then Claude writes you a CMS system that you check into a public GitHub repository unchanged, it’s not quite clear if that code is protected by copyright. However, if you prompt Claude Code with a specification and guidelines and then you work with Claude to refine the initial result, reviewing the code and making changes as part of an iterative process, then it could be argued that a human did produce that code. But it is not at all clear-cut legally. (Please note that I am not a lawyer.)
The current thinking is that the result of accepting verbatim the output of a simple prompt is not copyrightable, and that no one actually owns the code — an interesting notion in and of itself.
But then the ethical question comes into play. If I find a bug in an open source project, I ask GitHub Copilot to fix it, and Copilot writes a clever and effective fix, then who cares who owns the code? Should a maintainer of the project reject such a pull request just because it was AI-generated? That seems silly to me, yet it is happening today.
Our code
There is, too, the issue of license compliance for AI-generated code. As a general rule, LLMs generate code rather than copying it. They don’t copy and paste code directly from repositories. However, there have been cases where AI-produced code has resembled open source code so closely that the claim could be made that it is a copy. If this happens with GPL code, it could be a violation of the license to use it without the receiving code base being “infected.” Open source maintainers naturally should be concerned about this happening.
In the end, an open source maintainer should care about the quality and license compliance of submissions, not how those submissions were derived. Gatekeeping based on the source of code doesn’t seem like a good path towards project success. Good code is good code, no matter where it comes from.
Agentic coding is here, and the open source community needs to realize — and embrace — that inevitability.
{kind=link}
EDB converges analytics on Postgres to support AI agents 23 Jun 2026, 11:45 am
Separating transactional databases from analytical systems was, until recently, considered good architecture. Now, as enterprises adopt AI agents that continuously read, reason over, and act on business data, data warehouse and database vendors are increasingly deciding that separation has become a liability.
Just weeks after Databricks unveiled its Lakehouse Transaction and Analytical Processing (LTAP) offering based on Neon Postgres to bring operational (OLTP) and analytical (OLAP) processing closer together, EnterpriseDB (EDB) has introduced converged analytics capabilities for its managed EDB Postgres AI database service with the same intent.
Both vendors are responding to the same pressure of enabling AI agents for enterprises to operate on fresh operational data without waiting for pipelines and replicas, but EDB argues its approach starts from a fundamentally different place.
“Databricks is building from the lakehouse outward, trying to pull transactional capability in through Lakebase,” said Max Romanenko, chief engineering officer at EDB, while “we’re building from the operational layer with Postgres, which is where enterprises already run their most critical workloads, and expanding from there.”
In contrast to Databricks’ lakehouse-centric LTAP, EDB keeps Postgres as the operational source of truth and uses Apache Iceberg as a shared catalog layer connecting Postgres with ClickHouse, WarehousePG, and Spark compute engines, Romanenko said.
In this way, operational data remains in Postgres while historical and tiered data is stored in Iceberg-managed object storage, allowing analytical engines to query the same data through a common catalog without requiring separate copies or ETL pipelines, he said.
That architectural distinction matters to EDB, according to Romanenko, because the vendor is targeting enterprises that want AI and analytics capabilities without moving sensitive data into a cloud-managed platform: “For us, it’s always been about the data sitting on infrastructure the customer owns and controls.”
Focus on data sovereignty and predictable economics
EDB’s promotion of control “will resonate with CIOs focusing on sovereignty, regulated data, and hybrid deployment,” said Stephanie Walter, practice leader of AI stack at HyperFrame Research. “This should enable them to run AI and analytics closer to the data, on infrastructure that their enterprise controls, without creating yet another proprietary data estate.”
For Ashish Chaturvedi, leader of executive research at HFS Research, EDB’s approach in converged analytics will offer more predictable costs than Databricks LTAP for CIOs already struggling to manage their analytics and AI budgets.
EDB’s per-core pricing model can make costs easier to forecast than consumption-based cloud data platforms, where query volumes, AI workloads, and data processing demands can cause bills to fluctuate, Chaturvedi said.
But predictable bills are not necessarily lower bills, warned, Igor Ikonnikov, advisory fellow at Info-Tech Research Group. “The hardware requirements for high-speed operational data processing are higher and relatively more expensive compared to cheap lakehouse storage,” he said.
EDB’s architecture could also simplify data governance by reducing the number of platforms enterprises need to manage. Since operational, analytical, and AI workloads can access data through a common Postgres-Iceberg foundation, enterprises may be able to avoid deploying and governing multiple specialized data stores, and so have fewer systems to license and secure, according to Devin Pratt, research director at IDC.
Reducing architectural tax for engineering teams
EDB’s converged analytics could also simplify operations for developers and data engineering teams.
Its architecture reduces the number of systems developers must integrate and maintain, while eliminating much of the pipeline work traditionally required to move data between transactional and analytical systems, according to Walter.
And, said Pratt, “Zero-ETL means far less plumbing to build and break, so engineers spend their time creating value.”
EDB and Databricks are not the only ones pursuing converged analytics to support agentic systems and other applications needing immediate access to operational data, historical context, and governance controls.
Snowflake has been expanding support for operational workloads by embracing open table formats,and Microsoft has combined transactional and analytical services under a broader data architecture via its Fabric platform.
Evolution of autonomous databases?
Converged analytics, though, was only one part of EDB’s update to its Postgres AI platform.
It has also made generally available what it calls an “agentic database” feature, designed to automate routine database administration tasks.
The system continuously monitors hundreds of operational and performance metrics, detects anomalies, recommends corrective actions, and, where enterprise policies permit, can automatically apply fixes, the company said.
These automated agents can help enterprises optimize and tune their databases up to 10 times faster, it said.
Walter remained skeptical: “It is more an evolution of autonomous database concepts than a wholly new category. Oracle and other database vendors have offered autonomous database capabilities for years.” Where EDB can differentiate itself, she said, is in extending those autonomous capabilities with AI-driven reasoning, automated remediation, and governance controls that allow enterprises to determine how much authority the system receives.
{kind=link}
OpenAI rolls out AI-led push to fix open-source software flaws 23 Jun 2026, 5:35 am
OpenAI has launched a program with cybersecurity firm Trail of Bits to use AI to find and fix vulnerabilities in widely used open-source software, as enterprises face growing risks from flaws buried deep in their software supply chains.
The initiative, called Patch the Planet, uses AI-assisted vulnerability research alongside human review to help turn security findings into tested fixes that can be disclosed through existing project channels.
Initial participants include Python, Go, cURL, Sigstore, NATS Server, aiohttp, freenginx, pyca/cryptography, and python.org. These projects support software development, networking, cryptography, and supply chain infrastructure used across a wide range of enterprise applications and services.
OpenAI said each engagement will begin with consultation with maintainers to identify where security support is most needed. Researchers will then investigate potential vulnerabilities, validate meaningful issues, develop or refine patches, support testing, and coordinate disclosure through the project’s existing channels.
Participating security researchers will use the company’s models and Codex Security to analyze code and help move fixes toward release. Trail of Bits engineers will review findings before they are sent to maintainers, a step meant to filter out false positives and duplicate reports before they add to the workload of open-source projects.
The company is also working with HackerOne and Calif to support vulnerability triage, coordinated disclosure, and additional discovery work as the program expands.
OpenAI said work under the program has already identified “hundreds of security issues and merged dozens of patches, with many more still undergoing coordinated disclosure.”
The work has also produced tools for fuzzing, historical CVE analysis, and differential testing, along with systems to filter inaccurate findings before patches are generated, OpenAI added.
The focus on open-source security follows incidents such as Log4Shell and the XZ Utils backdoor, which showed how quickly a flaw in a shared component can move through enterprise software.
Analysts said Patch the Planet changes the risk equation only if enterprises treat AI-assisted vulnerability research as an input to a broader software supply chain risk program, not as a substitute for one.
“The key shift is speed: AI-assisted research can help find, validate, patch, test, and document issues faster, while human reviewers reduce false positives before maintainers are burdened,” said Biswajeet Mahapatra, principal analyst at Forrester. “But the dependency on scarce expertise does not go away; it moves to triage, exploitability judgment, patch safety, disclosure timing, and production rollout.”
Guardrails before deployment
CISOs should put governance controls in place before using AI-assisted vulnerability research in enterprise security pipelines, to ensure unverified findings do not overwhelm engineering teams, said Devashri Datta, an open-source cybersecurity architect.
“CISOs should demand a Safety Relevance Layer in their risk modeling, a structured framework that requires every AI-generated finding to pass automated verification, including dynamic proof-of-concept validation and strong false-positive filtering, before it reaches a human analyst,” Datta said.
Those controls should also cover disclosure, particularly when AI tools identify flaws in third-party open-source components that the enterprise does not control, Datta said. Organizations need predefined escalation paths, notification timelines, and role assignments that take effect once a confirmed issue is found in an external dependency.
“Ad hoc disclosure in an AI-accelerated environment isn’t just a process gap; it’s a liability,” Datta said. “Trusting AI in the production pipeline requires verifiable auditability: organizations must be able to trace why the AI flagged a line of code, how it validated the exploit, and how it determined that the patch would not break downstream production systems.”
Continuous exposure reduction
AI-assisted vulnerability research could force enterprises to move away from periodic patching cycles and toward more continuous risk assessment, analysts said. If variant analysis and differential testing can be compressed from weeks to days, security teams may need faster ways to decide which findings matter most in their own environments.
That shift also means enterprises can no longer rely only on generic CVSS scores to prioritize remediation, Datta said. Findings will need to be assessed against the affected system, its business role, runtime exposure and the likelihood that a flaw can be exploited.
“We have to move toward context-aware, safety-critical prioritization,” Datta said. “Enterprise SBOM and VEX programs must evolve from passive compliance spreadsheets into live, machine-readable data feeds. For AI-assisted pipelines specifically, that means extending the VEX model to cover AI-introduced risk surfaces.”
Mahapatra said vulnerability management programs will also need to become more closely tied to software ownership, supplier response, and business impact.
“Security teams should move from periodic vulnerability handling to continuous exposure reduction,” Mahapatra said.
That means SBOMs should be treated as live inventories tied to runtime exposure and supplier response, rather than static compliance documents. Patch decisions should also account for asset criticality, exploitability, compensating controls, and business impact.
The article originally appeared on CSO.
{kind=link}
The missing layer in enterprise agentic AI 23 Jun 2026, 4:00 am
In the past year, the enterprise AI ecosystem has gained enormous capability and zero consensus.
Developers now have a remarkable set of tools for building AI agents: OpenAI’s frameworks, Anthropic’s Claude tooling, LangChain, LangGraph, CrewAI, Microsoft AutoGen, and a growing list of alternatives. Each promises to coordinate reasoning loops, manage multi-step task execution, and connect agents to tools and APIs. For experimentation, the progress has been substantial. Teams can now assemble sophisticated agent workflows in days that would have taken months two years ago.
But I’ve watched this pattern before. In over two decades of building and selling distributed systems platforms, I’ve seen the same dynamic play out across nearly every major infrastructure shift: the tools for consuming a new capability arrive before the infrastructure for governing it does. The gap that emerges isn’t immediately obvious in development environments. It becomes obvious in production.
That’s exactly where enterprise AI stands today.
What agent frameworks don’t handle
Modern agent frameworks are fundamentally coordination systems. They determine what a system should do: which tools to call, how to sequence tasks, how to delegate work across agents. That’s hard work, and they’ve gotten quite good at it.
What they rarely address is where those tasks are allowed to run, and under what conditions.
Take a seemingly simple workflow: summarize customer support transcripts using an LLM. In a development environment, the implementation is clean. The agent calls a model API, passes the transcript, and returns a summary. In production at an enterprise, the same request may involve a dataset that can’t cross a specific geographic boundary, a model that isn’t approved for regulated data, and an audit requirement that demands a traceable record of what happened.
Those aren’t planning problems the agent framework was designed to solve. They’re execution governance problems. Most frameworks quietly assume they’re handled somewhere else in the stack. In many enterprise environments, they’re not handled at all. Gartner predicts more than 40% of agentic AI projects will be canceled by the end of 2027, citing inadequate risk controls as a primary driver of failure—a number that reflects exactly this gap.
What the missing layer actually does
Addressing these governance problems requires an additional layer between agent logic and execution: one that evaluates every agent action against policies governing where data can reside, which models may process it, who authorized the request, and how the action fits within the organizational context. The agent framework determines what the system should do. The orchestration layer determines whether and where it’s allowed to happen. Keeping those responsibilities separate allows both layers to evolve independently. It also means you can adopt new agent frameworks without rebuilding your governance model from scratch.
This separation will feel familiar to anyone who has worked through the Kubernetes era. Kubernetes doesn’t care what’s inside your container. It finds capacity, allocates resources, and ensures things run. The orchestration layer for agentic AI plays an analogous role: it doesn’t care which agent framework generated the request. It enforces the conditions under which that request can execute.
Richer authorization models
Traditional enterprise access control is built around a simple question: can user X access resource Y? That’s insufficient for autonomous agents.
A realistic authorization decision for an agent request might look more like this:
request = {
"agent": "support-summary-agent",
"task": "summarize",
"dataset": "customer_support_logs",
"model": "external_llm_api",
"delegated_by": "user_4821"
}
policy = evaluate_policy(request)
if policy.allowed:
route_to_execution(policy.execution_environment)
else:
raise AuthorizationError(policy.reason)
The policy engine here evaluates dataset classification, model approval status, geographic processing rules, and the delegation chain that initiated the request. That might mean redirecting the task to an internal inference cluster instead of a public API endpoint, or blocking the request if no compliant execution environment exists. From the agent’s perspective, the task still executes. The orchestration layer ensures it runs in an environment that satisfies enterprise policy.
Why ontologies are load-bearing infrastructure
For the orchestration layer to make good decisions, it needs to do more than label data. It needs to understand how the entities involved in a request relate to each other, and reason over those relationships to determine what’s allowed.
Consider the customer support transcript example again. Metadata tells you the dataset contains PII (personally identifiable information). An ontology lets the system reason across a connected chain: the task operates on a dataset containing personal data; that data is governed by GDPR; the organization’s policy requires processing within an approved EU environment; the selected model runs outside that boundary. From those four connected facts, the orchestration layer can infer the request must be rerouted or blocked. The system reasoned over the relationships rather than matching against a hardcoded rule tied to a specific dataset.
This is what makes policy enforcement, execution routing, data locality, and audit decisions computable at runtime. An ontology can be built around virtually any entity-relationship set the enterprise needs to govern: datasets, models, agents, users, regulations, tasks, environments. The relationships that matter are the ones that drive the decisions the governance layer needs to make. Access control lists can restrict who touches a resource, but they can’t reason across a connected set of entities. That reasoning is what the orchestration layer depends on.
Decision provenance as a first-class requirement
Enterprise systems also require auditability. When automated agents trigger actions across multiple systems, organizations must be able to reconstruct the decision path that produced the outcome. Compliance depends on it. So does incident response and basic operational trust.
An orchestration layer generates records describing the initiating identity, the agent, the model, the data sources, the policies evaluated during authorization, and virtually anything else the organization chooses to capture in its ontology. That chain of custody allows teams to investigate incidents and validate compliance without treating production AI systems as operational black boxes.
Regulators and auditors are no longer satisfied with knowing what an AI system was designed to do. They want a factual record of what it did in a specific instance, under what authorization, and with what effect—something dashboards can’t provide, but a well-designed orchestration layer can. The EU AI Act makes this explicit: under Article 12 and Article 17, high-risk AI systems must maintain documentation that makes decisions traceable and auditable, with records sufficient to support investigation after the fact.
Where this leaves enterprise teams
Agent frameworks will keep improving. The coordination problems they solve are real, and the ecosystem will continue to mature. But the architectural challenge for enterprises has shifted. It’s no longer primarily about coordinating agents. It’s about governing how those agents interact with real infrastructure, real data, and real compliance obligations.
The patterns for doing that exist today: contextual authorization, data locality enforcement, ontology-aware policy evaluation, decision provenance. What most organizations are missing is the recognition that these capabilities belong in a distinct layer that operates independently of whichever agent framework sits above it. Build that layer, and the rest becomes manageable.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
How fuzzy APIs are remaking the web 23 Jun 2026, 4:00 am
For nearly as long as the web has existed, web development has wrestled mightily with the right way to connect components over the network. This is the question of the remote API. It influences every aspect of the software we build. We sort of arrived at a tolerable compromise with JSON APIs. While these have their limitations, you have to appreciate their underlying simplicity.
But the advent of AI-enabled endpoints that can mediate intent is changing the basic workings of the internet. This change is gradually reawakening an old dream, the service-oriented architecture (SOA). This time around, with luck, we’ll finally gain the flexible, discoverable, and maintainable automated service discovery we’ve longed for. Fingers crossed.
Why old-school SOA failed
Let’s call this burgeoning influence of AI on web architecture SOA 2.0.
To understand why SOA 2.0 is different from SOA 1.0, we have to remember the trauma of the 2000s. (This may be painful but also cathartic.) The original dream of SOA was beautiful: a world where disparate business services—inventory, billing, shipping, you name it—could automatically discover each other, understand capabilities, and orchestrate complex tasks without human intervention.
To achieve this, we built a monument to complexity. We had SOAP (Simple Object Access Protocol) for messaging, WSDL (Web Services Description Language) to define contracts, and UDDI registries for service discovery. At the center of it all sat the Enterprise Service Bus (ESB), a massive piece of middleware that was supposed to route everything gracefully, seamlessly. In case you young’uns are confused, that is all based on XML.
By the time you were done understanding the infrastructure well enough to know how to do something, you had forgotten what you set out to do.
It failed. It was egregiously heavy. Just to do some simple thing like create a “New Item” endpoint, you immediately had to begin scaling a wall of rigid definitions.
Because computers historically required absolute, deterministic perfection, if a single XML tag in a SOAP envelope was missing, or if a service updated its WSDL without every client re-generating its stubs, the entire multi-million-dollar pipeline would violently unravel. Some of us may be familiar with a similar challenge in containerized microservices (like Kubernates), where trying to determine where in the mesh a problem originated is… awkward.
Classic SOA was a house of cards, too brittle to survive the fuzzy reality of the internet.
The typical JSON API of today is a reaction against SOA. (It may be an overreaction.) We abandoned SOA for the relative simplicity of REST, giving up on the dream of autonomous service orchestration in exchange for manual integrations that just work.
The new intention-to-execution middleware
A sea change is already happening with app-level architecture.
The effect of AI endpoints in an app’s service profile goes beyond just a new capability. It changes how the rest of the services work together. The overall effect is something like the app gaining an understanding of itself, and what it can do. This is not dissimilar to what WSDL was supposed to accomplish. But instead of a hard-coded descriptor, where some person had to keep what was available and what was described in sync, you now have a layer that can accept dynamically produced descriptors and unite them with fuzzy user intention and produce meaningful action.
You tie in AI endpoints to bridge between what the user is trying to accomplish, with the various strict capabilities available. These capabilities may exist within the app at the back end, at the front end, or at another service layer. The main thing is that there is a flexible AI layer that mitigates the need to hard-code the links between services.
In classic SOA, the contract was a rigid, unforgiving WSDL document. In modern common practice, the contract is a strongly coupled RESTful endpoint. In SOA 2.0, the contract has a hitherto unknown degree of flexibility, thanks to the natural language capabilities of an LLM.
When a user or a system expresses an intent—say, “Provision a new staging environment for the billing service”—the AI middleware doesn’t look for a hard-coded, point-to-point integration. Instead, it digests the intent and performs semantic routing, consulting a registry and selecting the appropriate tools. That registry, rather than a heavy UDDI, might be a vector database of available internal API endpoints, or a collection of available functions.
Modern LLMs equipped with function-calling capabilities act as the ultimate dynamic orchestrators. They read the JSON schema of a target REST API, understand its parameters, and dynamically map the user’s fuzzy, unstructured intent into a perfectly formatted JSON payload. If a field is missing, the LLM can either infer it from context or pause execution to ask the user for clarification.
The brittleness of SOA 1.0 is replaced by a shock absorber. If the target API changes a parameter name from customerID to clientId, the AI middleware can read the updated schema and adjust its mapping on the fly. No client code needs to be recompiled. No stubs need to be regenerated. The multi-million-dollar pipeline survives.
When software becomes smart
These are not just abstract ideas. I recently did my taxes, using a popular mainstream service that I will not name. I had several unusual and grumpy areas to deal with, including the new crypto regulations. It was not pretty.
But what I was most struck by was how dumb the software was, compared to the AI chatbot I was using to help guide me. I wanted to be able to tell the (stupid) software what I was trying to do. Such as “Carry my NOL from last year!” Or “I don’t know if I need a schedule K, you tell me!”
I don’t want another chatbot. I mean, I already have a good chatbot. I want the application to be well-integrated with AI services that understand the app, understand my current situation within the app, and meet me at the level of intent, applying the lessons learned by others who have used the same tools.
This kind of targeted, intelligent leveling up of intention is, from all I can see, the next stage of software development, and it is going to be massive.
Latency, non-determinism, and other challenges
We are trading the deterministic brittleness of classic SOA for the probabilistic fuzziness of SOA 2.0. And that trade is going to be demanded with ever more insistence by users. But it comes with a new set of trade-offs.
First, there is the latency tax. The old enterprise service bus was heavy to configure, but at run time, the messaging was just routed XML. Injecting an LLM into the critical path of an application adds hundreds of milliseconds, if not seconds, of latency. For asynchronous tasks or complex orchestrations, this is a welcome trade-off. For real-time, high-throughput microservices, it is a deal-breaker.
Second, there is the problem of non-determinism. We spent decades training ourselves (and our systems) to expect that given input A, a system will always produce output B. That deterministic equation was our bottom line faith. The intent layer doesn’t work that way. An LLM might route a request beautifully 99 times, then hallucinate a parameter on the 100th. Or it might choose an entirely different execution path based on a subtle shift in the user’s phrasing.
A third fly in the ointment is the so-called non-functional requirements, or NFRs. These are your pesky sidebar issues that refuse to be ignored, like security and reliability.
Security concerns are magnified by model capabilities like function calling (or “function passing”). If you pair a user’s desires with what the AI can do, and you then let the AI decide, what happens next is clearly an act of faith unless guardrails are put in place. These guardrails must go beyond typical web security (i.e., make sure important function calls are hardened on the server, not exposed on the client) and must be internalized by the AI or (more likely) imposed from a layer outside the AI. There are a number of ways to do this, varying in degree of power and complexity.
We certainly will continue to use standard practices (like RBAC and SSO) to enforce authentication. We will continue to implement standard authorization techniques (like OAUTH and JWT). But we will bring these to bear in the context of that intent layer and its capabilities.
Reliability is another challenge. For example, I recently hit a snag with Google’s Imagen API. Everything was working beautifully, then suddenly, some of the images stopped generating. There were no errors in the client or server logs; however, there were 500 errors in the network. Upon deeper examination, the prompting had morphed (between app context and user content) to include what the Imagen API rules deemed to be dangerous content. This was not obviously flagged prompting. It was fairly pedestrian creative writing, along the lines of “A dark, surreal, and glitchy cyberpunk landscape with menacing figures….” That kind of thing.
These are some of the ways that even simple, direct use of LLM APIs can surprise you. The question I am mulling is, what will be the unexpected outcomes on software writ large?
Dawn of a probabilistic web
Since its inception, the unpredictable, probabilistic nature of the internet came primarily from the humans using it (and background radiation flipping transistors, network failures, geopolitical effects on the ground, and the like). But AI-mediated APIs introduce an intentional, semantically controlled form of probability.
As developers, we will naturally discover the techniques that make consuming AI endpoints more effective. Here I am thinking about practices like structured responses and function calling. But the larger question is, what will the nature of software become?
In a world of binary states, strict protocols, and rigid URIs, if you send a GET request to a specific endpoint, you expect an exact, predictable response. We have spent the last 40 years treating the web like a vast, unimaginably complex state machine.
But as LLM-mediated APIs permeate our architecture with stochastics, the very fabric of the internet begins to change. By injecting AI into the routing and discovery layers, we are introducing a massive dose of probability into the foundation of our networks. When a request is no longer a hard-coded URI call but a natural language intent parsed by an LLM, the connection between node A and node B ceases to be a rigid wire. It becomes a weighted probability.
In essence, we are remaking the internet to mirror the architecture of the AI models we are deploying. Just as a neural network relies on the probabilistic firing of synapses rather than deterministic if/then statements, the next iteration of the web will rely on fluid, semantic discovery. Services won’t just “link” to each other; they will gravitate toward one another based on the conceptual proximity of their capabilities within a shared latent space.
This alters the character of software engineering. We lose (the illusion) of being entirely in control. Its strange paradox is that engineering using explicitly probabilistic components may make for a more resilient system. There is a longstanding debate about the best metaphor for software development. For the longest time, the construction of a building always seemed to be an apt analogy, or perhaps the mechanics of a vehicle. But these days, the gardening or cultivation metaphor is looking ever more relevant.
Despite the challenges posed by inserting AI in the stack, we are finally circling back to the original promise of the early 2000s. This time, fingers crossed, we are equipped with the right tools for the job.
We tried to build autonomous service discovery using rigid logic and deterministic XML, and it collapsed under its own weight. Now, we are building it with neural networks that understand the “intent” behind the integration. We are still building middleware, but instead of an enterprise service bus, we are building an enterprise reasoning bus.
The era of manually hard-coding every integration between every microservice may be coming to a close.
{kind=link}
Europe’s cloud sovereignty push may backfire 23 Jun 2026, 4:00 am
The European Commission’s latest push to reduce dependence on foreign technology providers is not surprising. If Europe believes that critical digital services could be disrupted by foreign governments, foreign legal systems, or foreign-owned providers, it will, of course, respond. That concern is now being expressed in the language of “kill switch” risk, meaning the fear that the cloud, AI, or semiconductor services that Europe depends on could be interrupted or constrained by forces beyond its control.
At a high level, that concern is valid. Europe is right to worry about strategic dependence. If critical public services, regulated workloads, or national-interest systems rely on infrastructure controlled elsewhere, sovereignty becomes more than a policy slogan. It becomes an architectural issue. However, I am skeptical of the leap from identifying the problem to assuming that a policy response will produce a cleaner, safer, or even more sovereign market. There is a good chance it may do the opposite.
What Europe is trying to protect
The motivation behind this effort is clear. Europe wants to reduce its dependence on cloud computing, artificial intelligence, and semiconductors from providers it does not fully control. It wants to ensure that core digital services cannot be switched off, legally constrained, or strategically influenced from outside the region. That is the public policy objective, and from a government standpoint, it makes sense.
The problem is that cloud markets don’t often respond to political intent as policymakers hope. The public cloud market is concentrated among a few big providers because scale matters. The hyperscalers have built global infrastructure, extensive services, ecosystems, and operating models that smaller regional players can’t match. Enterprises chose them for operational advantages, not geopolitical reasons.
Europe now finds itself in a difficult position. It wants sovereignty, but it also wants the benefits of scale, reliability, feature depth, and cost efficiency that usually come from very large cloud providers. Those goals do not always align.
Sowing enterprise confusion
One likely outcome of this push is that European enterprises will become increasingly confused about which public clouds they should select or avoid. That is not a minor point. Most enterprises already struggle with cloud strategy when the drivers are technical, financial, and operational. Add political sovereignty requirements, and the market becomes even harder to navigate.
Enterprises will now need to ask a more complex set of questions. Is a US-based hyperscaler with a localized European operating model acceptable? Is a European-branded sovereign cloud built on American technology better? Is a regional provider safer simply because it is smaller and local, even if it offers fewer services, weaker security tools, less resilience, and a less certain long-term future? At what point does “sovereign enough” become a legal or political judgment rather than a technical one?
This is where the market gets muddy. Policy discussions often imply a binary distinction between foreign and sovereign. In reality, cloud architectures are full of hybrids, partnerships, licensing arrangements, embedded dependencies, and supply chain layers, making neat categorization difficult. Enterprises do not buy cloud services based on a political slogan. They must navigate stacks of contracts, services, support structures, compliance obligations, and technical capabilities. The more politics enters that decision process, the less clarity there may be for buyers trying to make rational platform choices.
Sovereign clouds may not fix things
There is another reality that I think policymakers underestimate. Increased investment in sovereign cloud providers does not automatically create a durable sovereign cloud sector. In fact, history suggests the opposite.
Governments and enterprises may push investment toward smaller sovereign providers, but those providers still face the same brutal economics of the cloud market. They need capital, scale, customers, engineering depth, and ecosystem gravity. Many smaller providers will struggle to compete over time. Some will fail. Others will narrow their focus. Many will eventually be acquired, directly or indirectly, by larger players, including the very US-based cloud providers Europe is trying to reduce dependence on.
That’s the irony. Political pressure may spark a burst of sovereign cloud activity, but market gravity tends to reward scale. Sovereign cloud investment may create a temporary diversification, but in the long run, it could still end in concentration.
Sovereignty is not a bad goal, but the cloud business is structurally difficult. Running a competitive cloud platform is expensive. Matching hyperscaler capabilities is even harder. Enterprises eventually notice the gaps in services, AI tools, ecosystem support, geographic resilience, and operating maturity. When they do, they drift back toward the biggest and most capable providers.
Fragmentation comes before security
My concern is that Europe may be entering a period when cloud architecture is driven less by technical fit and more by political signaling. That rarely leads to simplicity. It usually results in fragmented strategies, duplicated platforms, inconsistent governance, and long procurement cycles.
Some organizations will choose a sovereign-first model for political reasons. Others will remain with hyperscalers but add contractual and architectural safeguards. Others will adopt a multicloud approach purely to avoid appearing overly dependent on one provider. Still others will split workloads by regulatory sensitivity, which sounds sensible until integration costs and operational complexity add up.
This is how confusion mounts. The question shifts from “Which platform best supports my workload?” to “Which platform is politically safest this quarter?” That is not a stable architectural framework.
Skeptical but attentive
I understand exactly why Europe is raising this issue. No responsible government wants critical digital services held hostage by external dependencies. That concern is rational, but rational concern does not guarantee rational market outcomes. My skepticism is not about whether digital sovereignty matters. It does. But can policy alone produce genuine long-term autonomy or will it create a more confusing procurement environment? At the same time, the market will quietly continue to consolidate around the largest global platforms.
The uncomfortable truth is that sovereignty is easier to announce than to implement. Cloud sovereignty is especially difficult because cloud markets reward scale, capital, ecosystem strength, and breadth of services. Those forces do not disappear simply because a regulator seeks more regional control. I think this issue will become more important over the next few years as cloud, AI, and geopolitical power become even more tightly linked. Europe is right to ask hard questions about dependence. But the answers are likely to be messy, and market outcomes may not look as sovereign as policymakers hope.
I don’t expect to see a clean break from foreign cloud providers. I do expect more hybrid arrangements, more sovereign branding, more enterprise uncertainty, more investment in regional providers, and eventually more consolidation than many people currently anticipate. That is not a failure of the idea. It is just the reality of how cloud markets tend to work.
The real challenge for Europe is not identifying the risk. It is building a response that does not create more confusion than the problem it is trying to solve.
{kind=link}
GitHub Actions hardens checkout security to block ‘pwn request’ attacks 22 Jun 2026, 6:43 pm
Stung by a surge in cyberattacks that have run amok in developer environments, GitHub has strengthened the security of actions/checkout to block ‘pwn request’ attacks that exploit insecure use of the pull_request_target workflow trigger to run an attacker’s code with the workflow’s full privileges.
Announced on June 18, actions/checkout v7 now automatically blocks and fails workflows when used inside pull_request_target or workflow_run events when attempting to fetch unreviewed fork pull request code.
From now on, the only away around these checks will be for developers to implement an opt out by adding an explicit allow-unsafe-pr-checkout to actions/checkout, GitHub said in its V7 changelog.
The change signals the beginning of a new ‘secure by default’ era in which security will be defined by the GitHub system rather than being left to discretion of developers. As part of that effort, on July 16, the new defaults will be backported to all supported major versions.
“Workflows pinned to a floating major tag (e.g., actions/checkout@v4) will automatically pick up the change. Workflows pinned to a specific SHA, minor, or patch version aren’t affected by the backport and will need to upgrade using Dependabot or through established upgrade processes,” GitHub explained.
However, because pwn request attacks can happen in other ways, “further hardening of additional events may be explored in future releases,” the changelog added.
Blind spot
If there’s a criticism that can be levelled at GitHub over this, it’s that it has taken so long to address a weakness that’s been known about for years.
The issue is with GitHub Actions, which allows triggers to run workflows, including pull_request, which processes third-party forks without giving access to secrets such as API keys, service tokens, and credentials. The downside is that this restriction prevents some automations from working, which is why developers turn to an alternative trigger, pull_request_target, which grants the required access.
At some point, attackers realized that where pull_request_target was configured carelessly with actions/checkout to pull in untrusted fork code, it offered a back door into repositories and their secrets.
In other words, the weakness in pull_request_target isn’t the trigger itself, which is legitimate and secure when correctly used, but in its incorrect use. As GitHub’s changelog puts it: “Checking out the head of an unreviewed pull request from a fork inside one of these workflows typically lets attacker-controlled code execute with the workflow’s full privileges.”
The arrival of actions/checkout v7, however, should make this harder, automatically blocking risky workflows regardless of their configuration.
Unfortunately, a lot of damage has already been done. Open source repositories have recently come under sustained attacks from the TeamPCP hacking group, using a variety of techniques, including pwn requests.
A notable example was its attack last month, which compromised 170 node package manager (npm) packages, including the TanStack Router ecosystem, thanks to a pwn request exploit. Embarrassingly, in a separate incident not involving a pwn request, GitHub itself was breached and the attackers exfiltrated source code from around 3,800 of the company’s internal repositories.
Better late than never, GitHub has sprung into action, plotting a series of security reforms on the platform, including, earlier this month, limiting automatic install script execution in npm.
{kind=link}
AWS Continuum offers devs help with securing code 22 Jun 2026, 11:30 am
AI coding agents are making it easier than ever to produce software. Ensuring that software is secure before deployment is another matter — one that AWS thinks AI should help with too.
As enterprises adopt agentic development workflows, the volume of first-party code being created and modified is rising rapidly. Yet the process of validating vulnerabilities, determining whether they are exploitable, and fixing them often still depends on developers and security teams working through findings manually.
AWS is aiming to address that imbalance with Continuum, a new service designed to continuously discover, investigate, and remediate vulnerabilities in enterprise environments, whether the code is their own or from third parties.
Rather than simply generating alerts, the service is intended to help enterprises move findings through the entire remediation lifecycle, AWS VP of Security and Observability Chet Kapoor wrote in a blog post.
For first-party applications, Continuum can analyze code, validate whether vulnerabilities are exploitable, generate remediation recommendations, and propose fixes that can be reviewed through existing software development workflows, helping developers address security issues without requiring security teams to manually investigate every finding, Kapoor said.
Once users think Continuum has learned enough about their environment and understands their guardrails, they can put it in what AWS calls “enforce mode” to autonomously fix any code lapses, Kapoor said.
Continuum borrows some of its capabilities, penetration testing and code scanning features, from an existing service, Security Agent.
Other capabilities are all-new, including threat modeling, which is designed to automatically generate threat models from source code or design documents and output them in STRIDE format.
Keeping pace with AI-driven software development
Analysts see Continuum helping enterprise developer teams ship more secure code while keeping pace with AI coding tools.
“The harder problem is no longer just finding issues, it is knowing which ones are real, which ones matter in their environment, and which ones need to be fixed first,” said Akshat Tyagi, associate practice leader at HFS Research. “Traditional workflows built around dashboards and manual triage struggle with that volume. A dashboard can show the backlog, but it does not validate the finding, assess business impact, or help remediate it.”
Continuum’s value, according to Tyagi, “is not just more detection, but using AI to prioritize risk findings, suggest mitigations, and support faster action while keeping humans in control of high-risk decisions.”
Taking faster action is becoming increasingly important as attackers are gaining access to many of the same AI capabilities that enterprises are using to accelerate software development and security testing, according to Amit Chandak, chief analytics officer at IT consulting firm Kanerika. “The gap between a flaw being disclosed and a working exploit is shrinking rapidly from months to hours,” he said.
While Continuum may reduce repetitive work for developers and SREs, it could also create new responsibilities for CISOs around governance, oversight, testing, and maintaining guardrails for automated actions.
“Continuum changes the CISO’s role from managing findings to governing how findings are handled. The focus moves to setting rules: what can be automated, what needs human approval, and what level of risk is acceptable in production,” Tyagi said. “Staffing will shift too. There may be less manual triage, but more need for people who can review AI-generated fixes, set guardrails, and know when not to trust the system.”
Even so, Chandak does not expect the offering to lead to immediate headcount reductions, particularly given that Continuum is only available as a gated preview.
Continuum could change how CISOs measure work, Tyagi said: “Ticket count matters less. Better measures are how quickly real risks are validated and fixed, how many false positives are removed, and whether automation is reducing risk without causing new problems.”
Those same metrics could also become a yardstick for CISOs determining how much autonomy to give tools like Continuum, said Chandak. Most enterprises’ data and governance practices are not yet ready for fully autonomous remediation, said Chandak, adding that, “AWS’ graduated trust design, under which enterprises have the option of choosing the degree of autonomy, from human in the loop to fully automatic remediation, is an admission of that fact.”
Beyond first-party code
Continuum could also help CISOs with third-party code vulnerability analysis, where enterprises often have less visibility and control.
“Most third party vulnerability alerts are noise. A tool may flag a vulnerable library, but the real question is whether that vulnerable code is actually used in production. If Continuum can answer that, it helps teams focus on the few issues that matter,” Tyagi said. “This is especially useful for open-source and software supply chain risk, where enterprises depend on packages and hidden transitive dependencies they may not fully track. It also helps when no patch is available yet.”
However, he warned, Continuum might not offer a direct fix to third-party code: “You usually cannot patch third-party code yourself as you don’t own it, so remediation there means version pinning or compensating controls.”
{kind=link}
Is Mistral late or savvy? 22 Jun 2026, 4:00 am
For the past few years, the most visible corner of the AI market has been easy to caricature: OpenAI gets the consumer attention, Anthropic gets the developer love, Google gets the benefit of the doubt with increasingly capable models and a complementary product suite, and everyone else gets to explain why they’re not dead yet.
That’s unfair, of course, but not completely wrong. In AI, attention compounds and it’s leading to outsized revenue, with both OpenAI and Anthropic reportedly rushing toward trillion-dollar-sized IPOs on the backs of billions in revenue.
So it’s easy to underrate Mistral AI.
Honestly, I hadn’t thought of the Paris-based company for a year. Maybe longer. But then Brian Hall announced he’s joining Mistral as CMO, and I had an Arrested Development “Her?” moment. Hall, a longtime Microsoft exec, hired me at AWS and went on to run product marketing at Google Cloud. His move prompted curiosity because Mistral doesn’t dominate developer chatter in the United States or boast the same seemingly endless compute budgets as Anthropic or OpenAI. If the AI market is simply a race to build the biggest, most magical, most general-purpose model, Mistral isn’t the company to bet on.
But that’s the wrong question, and likely the wrong bet.
The more interesting question is when the enterprise AI market will revert to type and demand that AI deliver the same security, predictability, and control we’re used to from other IT investments. Here Mistral has a real story. As Hall notes, Mistral’s approach is to “prioritize AI for mission-critical environments that need the confidence and self-control to bet for the long term (with open weights and real sovereign capabilities).”
While this might have sounded like an overly hopeful talking point, it became real in June when the US government ordered Anthropic to suspend access for foreign nationals to its most advanced Fable 5 and Mythos 5 models. Anthropic said it would disable the models for all users because of the export-control directive. “Can this vendor be forced to turn us off?” is no longer a theoretical question.
That’s why Mistral’s quiet focus on enterprise control just might work.
The wrong race
The enterprise control story is much more compelling than the narrative I used to hear. You know, the “Europe needs its own OpenAI” schtick. There is a market for “patriotic AI,” but it’s relatively small. The far bigger market is comprised of enterprises that just want AI that works, costs less (or delivers more) than expected, and can be customized while fitting their compliance requirements.
Though the company’s initial launch page went out of its way to mention that the company was operating out of Europe and headquartered in Paris, since at least October 2023 Mistral’s product posture has centered on enterprise control. Scattered throughout its current (and past) website are words like “customize,” “fine-tune,” “open source,” and “complete control.” Mistral pitches Studio for building and running AI apps, Forge for custom model training and alignment, Vibe for agentic work, Vibe for Code for coding workflows, and Compute for training and inference infrastructure. The company talks about observability, evals, guardrails, deployment portability, and running production AI “from edge to cloud.”
In other words, it sounds less like a chatbot company and more like an infrastructure company.
That positioning becomes clearer when you look underneath the product names. Mistral AI Studio includes an AI Registry that acts as a system of record for agents, models, data sets, judges, tools, and workflows. It tracks lineage, ownership, and versioning. It enforces access controls and promotion gates before deployment. That’s boring governance plumbing (and “boring” is good in enterprise IT, as I’ve written).
Forge may be even more important. Mistral describes it as a way for enterprises to train frontier-grade models on proprietary enterprise data. Rather than training on others’ copyrighted information strewn across the web or on a mountain of Reddit posts, Forge goes well beyond retrieval-augmented generation (RAG) to not simply “read in” proprietary docs/info/etc., but rather to give an enterprise its own private OpenAI, as it were.
That’s super interesting.
But is it different? I mean, OpenAI and Anthropic can do plenty of this, with greater scale and the benefit of leading frontier models. Both have enterprise products, cloud partnerships, evals, agents, governance tools, and varying forms of model customization. Mistral’s bet with Forge isn’t that the big labs can’t customize models. It’s that some enterprises aren’t interested in customization as a side feature bolted onto a frontier API. It is the product. OpenAI and Anthropic can build everything around Forge but not Forge itself, because the one thing they almost certainly aren’t interested in selling is independence from them.
This is where Mistral may have found a useful seam, one that allows it to ask a different set of questions. What if the best enterprise model isn’t the smartest general-purpose model? What if the best model is the one that’s small enough to run where the customer needs it, open enough to inspect and adapt, cheap enough to use broadly, and specialized enough to do the job? What if “good enough, governable, and your own” beats “slightly smarter, mostly opaque, and rented”?
This won’t matter for every use case, of course. If I’m asking AI to reason through a spreadsheet or write code, I probably want the best model I can get. But for banks, defense agencies, manufacturers, utilities, telcos, and governments, “best” is multidimensional and includes questions like latency, auditability, etc. It’s why banks, for example, still run so many workloads on premises: They want control.
What about compute?
None of this makes compute irrelevant. But it may change how compute matters.
If Mistral is trying to be a French version of OpenAI, its lack of hyperscale compute is a fatal weakness. It won’t outspend OpenAI, Oracle, Microsoft, Google, Amazon, SpaceX, or Anthropic. It probably won’t out-recruit them across every frontier research area, either. The AI market is already littered with companies that underestimated how quickly “good model” became “not good enough.”
But if Mistral is trying to become the enterprise-controlled AI layer for organizations that don’t want all intelligence to live behind someone else’s API, compute becomes a more nuanced issue. It still needs infrastructure, and Mistral seems to know it. After all, Mistral raised $830 million in debt to buy 13,800 Nvidia chips for a data center near Paris. That’s a rounding error compared to OpenAI and Anthropic, of course, but the real question is whether Mistral can turn relative compute scarcity into a virtue, like Amazon’s Leadership Principle “Frugality” on steroids. If lower compute capacity leads Mistral to deliver smaller, more efficient, and more specialized models, which in turn helps enterprises maintain more control of their data at lower cost, then less really does become more.
Mistral’s compute challenge, then, is not to try and have as much compute as OpenAI. It’s to make customers care less about raw compute scale and more about deployment flexibility, specialization, and control.
That’s a hard sell. But it’s not a dumb one.
What Mistral must prove
The bear case remains obvious. OpenAI has consumer distribution, developer mindshare, capital, and a brand that has basically become synonymous with AI. Anthropic has become the developer darling and has an unusually strong enterprise story of its own. Google has the models, the infrastructure, the data, and a bevy of complementary services. AWS, Microsoft, and Oracle have customer relationships and infrastructure.
Mistral has to prove that there’s room for another center of gravity. More specifically, it must prove three things.
First, it has to show that open-weight and controllable AI matter enough to influence buying decisions, not just conference panels. Everyone says they want control, just as most like the idea of open source. But proprietary software and cloud services still dominate the market. Mistral must make control feel like the easy button.
Second, it must prove that specialization beats generality in enough high-value markets. “Our model is almost as good” is not a strategy. “Our model is better for your bank, your government agency, or your retailer” just might be.
Third, it needs to establish a beachhead within enterprise IT before OpenAI and Anthropic become “boring” enough to satisfy the same buyers. This is the real race. The biggest AI companies are hiring enterprise sales teams, building admin controls, and cutting deals with every major cloud. Mistral’s window exists because the market is still young, but that window won’t stay open much longer.
If AI remains a model benchmark race, Mistral likely loses. But if AI keeps evolving to become grown-up enterprise infrastructure, Mistral has a real chance.
{kind=link}
Why open infrastructure will define the AI era 22 Jun 2026, 4:00 am
A new form of vendor lock-in is here. And it’s not proprietary languages or rigid enterprise software suites — it’s something more fundamental. It’s the very thing that writes the code.
JetBrains Research found that 74% of developers worldwide use AI tools. Claude Code, available only since May 2025, is now the most popular AI coding tool, followed by Gemini Code Assist and GitHub Copilot, according to Jellyfish’s 2026 State of Engineering Management Report.
The latter study also found that 91% of developers say their productivity has increased in the past 12 months. As coding output expectations are rewritten daily, the engineering world is becoming heavily reliant on paid external AI services.
Gartner predicts that by 2028 spending on AI coding tokens could exceed developer salaries. Yet, tokenmaxxing while vibe coding through a vendor’s cloud-based API feels like a far cry from the open foundations of free programming languages and open models, which many of today’s AI platforms now abstract.
“Open infrastructure will be the backbone of the AI era,” says Peter Farkas, CEO of Percona, a provider of open-source database solutions. “Right now, too many companies are building their entire AI strategy on top of proprietary platforms because the convenience is seductive.”
“It’s ‘three clicks’ to stand up a database or an AI service in a hyperscaler, and that convenience blinds people to the lock-in they’re signing up for,” he adds. “As AI workloads mature, organizations will realize that depending on one vendor for their data, models, runtime, and pricing is not a strategy.”
AI-assisted coding is democratizing software engineering for non-engineers and accelerating top performers. But if teams are always working within the confines of how one platform thinks the world should work, it could create locked-in toolsets at scale. And as AI platform costs rise, a fundamental question arises: will software developers consume AI on their own terms, or on someone else’s?
There’s a strong case that the long-term winners in tech will be built on open-source standards and foundations, similar to the history of cloud-native computing and the internet itself.
“Open always wins,” says Brian Alvey, CTO at WordPress VIP, a managed WordPress hosting platform. “Not because it’s a fancy ideology, but because it gives you total freedom to adapt, evolve, and stay in control.”
Open infrastructure avoids a future where developers perpetually rent. “For AI to be useful to people at large, it can’t be something you’re paying rent for the rest of your life,” says Manik Surtani, CTO and co-founder of the Agentic AI Foundation (AAIF), a vendor-neutral home for open-source agentic AI technologies. “And it can’t be concentrated in one particular corporation or a small handful of corporations, because we know how that goes.”
Pricey, closed, proprietary AI
AI development today is traveling two parallel paths. On one path, open-source AI is thriving and fueling tremendous growth in the number and variety of AI models and tools. Just take the thousands of open-weight models on HuggingFace, the community around the OpenClaw AI agent, or the many academic institutions publishing new breakthroughs.
“Open-source models and tooling are hot on the heels of state-of-the-art, with interesting and boundary-pushing work being shared by labs and researchers across the world,” says Austin Parker, director of AI strategy at Honeycomb, an observability platform provider, citing frontier open-source models like Mistral, DeepSeek, and Ai2’s OLMo as examples.
Others agree. “There’s unprecedented openness at the model and tooling layer, with open-source models, frameworks, and orchestration advancing at remarkable speed,” says Mark Collier, general manager of AI and infrastructure at the Linux Foundation.
On the other path, we’re seeing heavy reliance on proprietary AI systems controlled by Anthropic, Cursor, Google, Microsoft, OpenAI, and others. As Collier says, “Many platforms are wrapping those open components in closed, opinionated interfaces that trade short-term speed for long-term constraints.”
Open source and the AI tooling market don’t always mix well. LangChain’s Open Agent Platform, for instance, was open-sourced to much fanfare in 2025, but by 2026 had been deprecated, with the repository now recommending fully managed alternatives.
For Roman Shaposhnik, co-founder and CTO of Ainekko, provider of an open-source, composable AI stack, the current AI platform landscape is reminiscent of low-code and no-code platforms, which promised democratization of software development but often failed to deliver, becoming synonymous with platform lock-in and inflexibility.
“Honestly, it feels familiar,” Shaposhnik says. “We have incredibly powerful AI tools right now, but most of them come bundled as tightly controlled platforms.” This is a risk for AI, he says, because the infrastructure, models, and hardware are tightly coupled. “If those layers are closed, you lose flexibility fast.”
Some abstractions that sit on top of models, like routing and agent frameworks, tend to be tightly coupled and optimized for certain models. Other platforms take the walled garden concept quite literally. Anthropic, for instance, has repeatedly made headlines for blocking access to its Claude models over vague policy violations. The company recently shut off competitor xAI’s use and stonewalled OpenCode, drawing community backlash.
Moves toward increasingly closed systems don’t bode well for an AI economy already built on shaky economics. As Vikram Srivats, head of product experience at WaveMaker, provider of an agentic application development platform, adds, “Given the unit economics of AI tooling and pace of accelerated change to keep up, it seems obvious that some will evolve to more of a closed system to be able to monetize and gain ROI.”
Why openness matters in the AI era
Reliance on proprietary AI platforms can create long-term operational dependencies. As systems become less interoperable, organizations may be forced to standardize on a single stack across data pipelines, models, and decision logic, says the Linux Foundation’s Collier.
“As infrastructure consolidates, enterprises become more exposed when platforms change direction, raise prices, or fall behind technically,” he says. “If you can’t change platforms without re-architecting your AI systems, you’ve already given up too much control.”
“When you build on someone else’s platform, you have to live by their rules and those rules always change,” adds WordPress VIP’s Alvey. “We’ve all seen this before, businesses wasting time and money building to serve Google, Facebook, YouTube, and the App Store, instead of building to serve their customers.”
Platform lock-in can also create direct business risk. As Ainekko’s Shaposhnik says, “It usually shows up as higher costs, fragile systems, and growing risk when it’s time to change direction.”
At Ainekko, an internal group called the AI Plumbers focuses on back-end AI infrastructure like inference, scheduling, memory, and hardware integration. “Their view is simple,” says Shaposhnik. “If those layers are closed, everything above them becomes fragile.”
Open standards, interfaces, and infrastructure provide a necessary hedge against closed systems to prevent this sort of fragility. “In the AI era, open infrastructure gives enterprises control, portability, and choice at exactly the time they need it most,” says Percona’s Farkas.
It can cost upwards of $100,000 to migrate enterprise software, according to Cloudaware, making portability a major enterprise concern. From this perspective, procuring closed systems can become a costly architectural dependency.
Others argue that openness is a critical hedge against vendor concentration risks at large, especially if AI replaces human labor en masse. “If all of that economic value is now being concentrated in the hands of one or two companies,” says the AAIF’s Surtani, “that’s an order of magnitude bigger problem than we’ve seen in any other wave of computing.”
Instead, open foundations allow adaptability to evolving conditions so enterprises can swap out models, agents, data, hardware, and orchestration, as needed. “Open standards let those components change independently without breaking the system,” says Collier.
Openness can also help future-proof businesses against economic upheaval. “Open everything will help build a cushion for businesses and users to survive and thrive after the almost-certain correction in the current hype cycle,” says WaveMaker’s Srivats.
Momentum toward open AI infrastructure
At the industry level, momentum toward open AI infrastructure is growing. The establishment of the Agentic AI Foundation, Anthropic’s donation of Model Context Protocol (MCP), and Block’s donation of its Goose agent are significant ecosystem-wide moves toward openness. Other advances include the donation of llm-d, a Kubernetes framework for LLM inference, to the Cloud Native Computing Foundation (CNCF).
For Parker, donations like this help ensure long-term support and care. “Open standards aren’t just the foundation of the internet, they’re the foundation of the AI space,” he says. “I predict that we’ll see these practices continue, especially as enterprise adoption increases in earnest,” he adds.
Still, some question whether this level of stewardship is enough for a rapidly evolving ecosystem. “The internet benefited early on from groups that helped keep vendors aligned,” says Shaposhnik. “In AI infrastructure, we don’t really have that yet.”
“All of us open source veterans are hopeful,” he says, “but we also need to adapt to this new reality in what we do regarding AI infrastructure.”
Beyond industry governing bodies, companies themselves are also spearheading open AI initiatives. Warp, an agentic development environment, recently went open source amid closed-source rivals. Arcade.dev, meanwhile, is pushing an open-source Agent Library for agentic memory.
Where openness matters most in the AI stack
While AI infrastructure can be open in many ways, a few layers stand out as especially important. First is the openness of the model itself. “Open-source models must be the foundation of future trust and value,” says WaveMaker’s Srivats.
“The forms of open infrastructure that reduce integration friction and accelerate adoption stand out,” adds Neeraj Abhyankar, VP of data and AI at R Systems, a global digital solutions provider. For him, open model representation formats, open orchestration and execution layers, open agentic protocols, and open governance and metadata standards are all essential for enterprise flexibility.
Others place more value on the connective tissue between AI components. “The most important forms of open infrastructure are the ones that connect systems together,” says Collier. “That includes open APIs, metadata standards, identity and policy frameworks, and protocols for how models and agents communicate.”
Arguably, MCP has become the connective tissue between AI agents and the broader API ecosystem. “If we get MCP right we unlock the same level of interoperability between entities on the web and models driving them as we came to enjoy during the Web 2.0 era and the API-first boom,” says Shaposhnik. “If we don’t we risk massive proprietary lock-ins.”
Parker agrees that open protocols will underlie future AI progress. “We’ll see continued development and progress on AI agents which will rely on protocols like MCP and ACP [Agent Client Protocol] to interoperate with various clients and each other,” he says. Yet a gap remains around API conventions for models. “It would be nice if we could get a commitment from model providers to use a standard here.”
For the AAIF’s Surtani, opening up the protocol layer is the most important aspect. “I think it’s really important for interoperability, for choice,” he says. “It means you can bring your own agent, you can bring your own framework, you can bring your own harness, and pick what model you want.”
Open standards may also play a significant role within inference architecture. “As AI expands to the edge, developers need visibility into how models run, how memory is used, and how performance scales,” says Shaposhnik. Open systems could make it easier to optimize, debug, and adapt while helping enterprises avoid observability fragmentation.
Lastly, cloud-native architectural standards are a key ingredient for open AI infrastructure. “We’re seeing Kubernetes become the missing link for people who want the hyperscaler-style convenience without hyperscaler lock-in,” says Percona’s Farkas. For him, Kubernetes has become the de facto hybrid enterprise deployment option for data, workloads, and AI components.
History repeats itself
The 2026 State of Open Source Report found avoiding vendor lock-in to be the primary driver of open source adoption. But beyond being a strategic decision for a single company, open infrastructure provides a layer for entire industries to be built upon.
Arguably, the internet itself is evidence of this, where groups like the IETF and the IEEE were instrumental in defining the fundamental protocols. “Without open protocols we would’ve been in telco hell and without phenomenons like Google or Facebook,” says Shaposhnik.
Or, take the history of Linux as a parallel. “Linux became the default operating system because it offered a common, vendor-neutral foundation that everyone could build on,” says Collier. “In the AI era, open infrastructure will define the layers that organizations rely on for long-term continuity.”
At the infrastructure level, open standards have repeatedly underpinned major platform shifts, from Docker to Kubernetes. The question now is whether AI will develop a similarly durable standards layer.
For Parker, it’s too early to say, but the current growth of AI mirrors the early cloud. “Remember that it took many years before we saw the development and popularization of the open source cloud-native ecosystem,” he says. “I think it would be a mistake to extrapolate from the current trajectory towards a closed, proprietary future.”
Others agree the future must be rooted in openness. “I see open infrastructure becoming the foundation of enterprise AI,” says R Systems’s Abhyankar. “As systems become more distributed and agent‑driven, closed ecosystems simply won’t scale.”
The groundwork is being laid through open agentic protocols, open frameworks, and industry support intended to reduce fragmentation around proprietary standards.
“Ironically, the AI movement has mostly seemed to learn from the mistakes of the past and is starting off on a more open foot,” says Parker. “Over time, I believe we’ll see innovation and openness thrive.”
{kind=link}
Researchers grow a hypothesis tree for AI coding agents 19 Jun 2026, 5:16 pm
AI coding agents can tend to isolate research, running experiments and generating ideas that are then forgotten when context windows reset. This can waste tokens, as models then repeat the same mistakes and hit the same dead ends.
But new research argues that it’s not the model itself, but the overarching ‘tree,’ that needs tweaking. To that end, data scientists from the Gaoling School of Artificial Intelligence, Renmin University of China, and Microsoft Research have introduced Arbor, a “persistent hypothesis tree” that helps agents remember and refine learnings over long research sessions.
A long-lived coordinator manages research strategy across the tree, while short-lived executors spin up isolated worktrees to test different hypotheses. As results come back, the tree updates, narrowing and refining throughout experimentation.
In practical tests, this technique delivered more than two-fold performance gains over standard AI coding agents across real-world engineering tasks, for the same budget.
This is because, said Mahmoud Ramin, a research director at Info-Tech Research Group, “Arbor accumulates information over time and allows agents to build upon prior discoveries just as humans do, through learning, adaptation, and eventually building upon what they have learned in the past.”
How Arbor grows
Arbor’s builders argued that longer execution on its own does not guarantee research progress. The challenge is maintaining a state that turns many individual attempts into “cumulative hypothesis refinement.”
Further, progress should not depend on human overseers regularly stepping in to dictate logical next steps or interpret the meaning of previous trials, they noted. To be truly autonomous, agentic research frameworks must maintain connections between experiments, data, results, and failures over time.
Arbor is built to fulfill three system requirements. First, it must be able to branch as sub-trees test out competing hypotheses that are all potentially plausible. At the same time, unrestricted branching can degenerate the whole framework, so that must be controlled to remain organized. The researchers call this “branching with coherence.”
Second, the infrastructure must separate local execution from overarching strategy. Testing out single hypotheses requires short-horizon tasks like editing, debugging, and evaluation. But these should not “obscure” the larger tree making decisions based on evidence gathered across the whole run.
Finally, the systems must be able to distinguish exploratory improvement from verified improvement. This prevents AI from overfitting during trial-and-error instead of iteratively learning from underlying patterns.
Persistence is at the core; the tree links hypotheses and ideas, the code or configuration artifacts used to test them, experimental evidence (results, metrics), and distilled insights (such as “this data filter helped, but this learning rate scheduler didn’t”).
Once a project kicks off, shorter-execution work trees run code, log their work, and collect metrics. The long-lived coordinator above them serves as the de-facto head of research, keeping an eye on the process, updating nodes, selecting “promising leaves,” pruning or merging branches, propagating reusable lessons, and deciding which hypotheses to pursue next.
“The tree therefore acts as the operational research state of the system,” Arbor’s builders wrote. “It is simultaneously the search frontier, the memory of past attempts, and the audit trail for verified artifact improvement.”
Outperforming Codex and Claude on new data
To test how well this process works, the researchers evaluated Arbor in an autonomous optimization (AO) setting: the agent was given an initial research artifact (a data pipeline, harness, or training script) and was tasked with improving its “held-out performance” through iterative experimentation, without human steering. Held-out performance is a machine learning (ML) metric that evaluates how well models are able to generalize on data they haven’t seen before.
The tree-based architecture was tested on several real research tasks across model training (its ability to improve training recipes and hyperparameters), harness engineering (how well it can upgrade evaluation or training harnesses), and data synthesis (its capacity to generate better data for training or evals).
Ultimately, Arbor outperformed the average held-out gains of Codex and Claude Code by 2.5x, for the same resource budget.
The takeaway, said the researchers: Keeping a structured, evolving hypothesis tree yields greater performance improvements than running the same models as ‘memoryless’ coding agents.
Arbor’s most innovative feature is its ability to maintain the agent’s memory and retain relevant data from prior attempts and hypotheses, Info-Tech’s Ramin pointed out, and, he said, “the next step for autonomous agents may be accumulating evidence over time.”
However, this does raise concerns about the auditability of robust research environments at a large scale, he noted. “As autonomous agents become more capable of performing work without human operators overseeing them, enterprises will need transparency into how and/or why an agent took a specific action or reached a certain conclusion.”
{kind=link}
Solving an ARD problem in AI: Agentic Resource Discovery 19 Jun 2026, 11:37 am
Enterprises implementing agentic AI face a challenge: Which tools should they allow their agents to use, where can they be found, and how can they be used safely? A new protocol, Agentic Resource Discovery, or ARD, aims to let agents answer those questions for themselves. Behind it are Google, Microsoft, Cisco, Nvidia, Salesforce and others.
ARD aims to standardize the way that tools and services are shared across systems within a corporate domain. For example, when investigating a production problem, an agent may want to query engineering documentation and open support tickets, deployment history and observability systems, all of which could be managed by different registries and across different silos. There is no common layer that pulls them together. ARD has been designed to be that layer.
It operates across two levels. Catalogs and Registries. In the first, an organization publishes a catalog setting out its available capabilities. The Registries layer act as a form of search engine, crawling those published catalogs.
The ARD specification is available now. Organizations are invited to publish their own catalogs using the quickstart guide. After this, they are able to join the community and participate in the evolution of ARD.
{kind=link}
OpenAI gets the attention it needs from AI researcher Noam Shazeer 19 Jun 2026, 11:24 am
An IT executive changing jobs usually attracts little attention outside a narrow group of people, but Noam Shazeer’s move from Google to OpenAI is as momentous as any high-value soccer transfer.
He announced the news in a post on X: “I’m excited to share that I’ll be joining OpenAI and look forward to working with the exceptional team there.”
Shazeer initially achieved fame as one of the eight co-authors of the influential AI paper Attention Is All You Need, published when he was working at Google Brain. He is also one of the creators of the transformer technology that lies at the heart of modern AI models.
He left Google when the company failed to back his chatbot Meena and was tempted back when Google subsequently bought the company he founded, Character.AI, for $2.7 billion. That company achieved notoriety when it was sued by a grieving mother, who alleged that a Character.AI chatbot had contributed to her son’s death by suicide. The company subsequently settling out of court.
Shazeer has since been working as the co-lead on Google’s Gemini project. It’s not clear what role he will play at OpenAI, but hiring someone with his background shortly before the company’s IPO could be an attractive move for investors.
This article first appeared on Computerworld.
{kind=link}
Google, Microsoft offer specs to help you prove your AI is behaving nicely 19 Jun 2026, 9:54 am
Google, Microsoft, OpenAI, and others want to help enterprises demonstrate that their AI applications are behaving themselves through the creation of a new foundation.
The Appia Foundation will, it explained rather impenetrably, “establish modular specifications that provide a connecting layer to bridge foundational global standards with practical, trusted assessments across the global AI value chain.”
Those specifications will help AI users ascertain whether the systems they are using meet all the obligations that apply to them in the form of standards and regulations, it said. It’s a challenging task with so much regional variation in requirements, and where the EU, for example, is more tightly controlled than the US.
The Foundation has established a set of criteria to demonstrate conformity with what is expected. There are two layers: the Requirements and Guidance layers will help users determine what is actually required, while the Assessment Enablement layer will look at how those requirements are evaluated.
Appia stressed that what it is offering are not standards — which are set by recognized international bodies such as ISO/IEC — but a means of assessing what those standards mean and how they can be used by organizations. However, the Foundation said that some of the criteria that it is introducing may become standards themselves after a period of time.
The Appia Foundation is hosted by the Linux Foundation’s Joint Development Foundation, and its other members include Arm, Ericsson, Mastercard, Mitsubishi Electric, Omron, Schneider Electric, and Siemens. It is also looking to bring academics and government into the fold, so that it can establish an advisory board.
This article first appeared on CIO.
{kind=link}
AWS aims to take the pain out of RAG with Bedrock Managed Knowledge Base 19 Jun 2026, 4:26 am
For many developers, the hard part of building an AI application isn’t the model anymore. It’s keeping the application’s knowledge current.
Retrieval-augmented generation (RAG) has become a popular technique for grounding AI applications in enterprise data, but it also introduces a steady stream of operational work, including tasks such as updating embeddings and indexes, synchronizing data sources, and tuning retrieval performance.
AWS is seeking to remove much of that burden with Bedrock Managed Knowledge Base, a new managed service that automates the retrieval layer behind enterprise AI applications.
“By default, the service automatically selects and manages a default embeddings model, re-ranker model, and foundational model on your behalf, so you can get up to speed quickly without needing to pick or maintain one yourself,” Daniel Abib, senior solutions architect at AWS, wrote in a blog post.
In order to help maintain data pipelines without building and managing custom integrations, the service also comes with six native connectors for enterprise data sources, including Amazon S3, SharePoint, Confluence, Google Drive, OneDrive, and web content, Abib wrote.
Managed RAG could boost developer productivity
For developer teams, the ability to automatically manage infrastructure could provide an immediate boost in productivity, according to Pareekh Jain, principal analyst at Pareekh Consulting.
“Enterprises spend significant time building data connectors, managing document ingestion and indexing, tuning retrieval quality, enforcing access controls, and maintaining vector databases, often making the RAG infrastructure more complex than the AI application itself. With this, developers can now focus on building the application,” Jain said.
“That should accelerate deployment timelines and reduce maintenance costs while enabling teams to focus on business outcomes,” Jain added.
Beyond reducing infrastructure management overhead, Managed Knowledge Base also targets retrieval accuracy. The service, according to Abib, also comes with features, such as Smart Parsing and Agentic Retriever, which are aimed at helping improve accuracy across different content types and sources, which is often an issue with RAG pipelines and queries spanning multiple repositories.
Improved retrieval quality could prove particularly important for organizations looking to move AI projects from experimentation to production, according to Jain.
“This is a common challenge across enterprises because business data is scattered across multiple systems. As organizations move from AI pilots to production, retrieval quality becomes critical for user trust, making RAG infrastructure a major bottleneck that often delays deployments,” Jain said.
AWS is also positioning Managed Knowledge Base as a building block for agentic applications, which, Jain said, can place even greater demands on enterprise knowledge and retrieval systems.
The service, according to the hyperscaler, integrates with Bedrock AgentCore, reducing the amount of code and configuration required to connect enterprise knowledge sources to AI agents while providing built-in monitoring, evaluation, and access management capabilities.
Taking aim at RAG stacks?
That integrated approach could also have implications for the broader RAG tooling ecosystem, Jain said.
“Managed services such as Bedrock Managed Knowledge Base could reduce demand for standalone RAG orchestration and retrieval frameworks, including tools such as LangChain and LlamaIndex, as well as some custom combinations of vector databases, ingestion pipelines, and retrieval services,” Jain noted.
However, Jain cautioned that the convenience of an integrated approach comes with tradeoffs, potentially increasing customer dependence on a single cloud provider and limiting flexibility in how AI infrastructure is assembled and managed.
Amazon Bedrock Managed Knowledge Base is currently available across North Virginia, Oregon, Sydney, Tokyo, Dublin, Frankfurt, London, and AWS GovCloud (US-West) Regions.
The service follows a usage-based pricing model, with charges tied to the volume of indexed data stored and retrieval requests processed.
{kind=link}
Cloud at 20: How AWS shaped enterprise IT 19 Jun 2026, 4:00 am
It is tempting to date cloud computing from the launch of Amazon S3 in 2006 and the rise of infrastructure as a service (IaaS) that followed. That was certainly the moment the market changed in a visible, irreversible way. But the truth is that cloud began earlier, in the 1990s, when software as a service (SaaS), application hosting, managed services providers, and various forms of remote subscription computing started to reshape how enterprises thought about owning and operating technology. Even then, the core value proposition was familiar: Let someone else run the infrastructure, abstract the complexity, deliver capability as a service, and allow the business to consume only what it needs.
What AWS changed was the scale, accessibility, and precision of the execution. Amazon turned infrastructure into a programmable utility. It made compute and storage available in ways that were elastic, self-service, API-driven, and globally reachable. That was the breakthrough. Enterprises had outsourced pieces of technology before, but now they could rent raw infrastructure with unprecedented speed and flexibility. The launch of Amazon S3 was especially important because it provided a durable, scalable storage foundation that became one of the building blocks for modern digital business.
AWS changed everything
Technology markets are rarely transformed by the first company to think of an idea. They are transformed by the first company to make that idea operationally real, economically viable, and broadly consumable. AWS did exactly that. It built a model for infrastructure as a service that allowed enterprises, startups, and eventually governments to rethink the entire life cycle of IT delivery.
Looking back from 2026, it is difficult to remember how radical this concept once seemed. At the time, many enterprise leaders considered public cloud too risky, too immature, too uncontrolled, or simply too foreign for conventional IT governance. There were concerns about security, compliance, vendor dependency, performance, data residency, and reliability. Many of those concerns were valid. Early cloud adoption often ran ahead of cloud maturity, and many organizations discovered that moving quickly did not always mean moving wisely.
Still, the economics of agility overwhelmed the inertia of the old model. Provisioning that once took months could be done in minutes. Capital expenditure gave way, at least in part, to operating expenditure. Experimental workloads became easier to justify. Digital businesses could scale without building data centers first. AWS led that transition, and the rest of the industry followed, including competitors that helped mature the market.
Cloud’s strengths and liabilities
If the first decade of cloud was about acceleration, the second decade was about correction. Enterprises learned that cloud was not automatically cheaper, not automatically simpler, and not automatically better. It was better when used with discipline. It was more cost-effective when architected intelligently. It was more resilient when governance, operations, and security were designed into the system rather than added later.
This is when the industry grew up. We learned about cloud financial management because too many organizations assumed elasticity would control cost, only to discover that unused resources, poor workload placement, and fragmented accountability could drive spending far beyond expectations. We learned that public cloud could provide extraordinary innovation and reach, but also that not every workload belongs there. Latency, sovereignty, compliance constraints, legacy integration challenges, and predictable high-volume workloads all forced a more nuanced view.
We also learned about concentration risk. As enterprises standardized on a small number of hyperscalers, questions emerged around resilience, lock-in, and strategic dependency. The answer was never simplistic multicloud posturing for its own sake. It was architectural realism. Use the public cloud where it creates a clear advantage. Keep options open where business risk requires it. Understand portability, but do not romanticize it. In other words, cloud became less ideological and more practical.
Cloud is now an assumption
Perhaps the most important shift of all is that we no longer debate whether cloud is real or whether enterprises should use it. That argument is over. Cloud is baked into the cake. It is part of enterprise operating reality. The modern enterprise assumes on-demand infrastructure, platform services, automation pipelines, managed databases, identity fabrics, observability stacks, and globally distributed application delivery. Even when workloads remain on-premises or at the edge, they are often built, governed, or operated with cloud-native thinking.
This is maturity. Cloud is not a project or a trend. It is not even a strategy by itself. It is an enabling model that now underpins enterprise strategy. Businesses no longer ask whether to adopt cloud in the abstract. They ask how much cloud, which cloud services, under what governance model, at what cost profile, and in support of which business outcomes.
That may sound less exciting than the early days of disruption, but it is actually the mark of success. The most powerful technologies eventually disappear into standard practice. Electricity, networking, virtualization, and mobile platforms all went through this process. Cloud has done the same.
How cloud supports the AI race
As enterprises move aggressively into AI, cloud has entered another pivotal phase. AI is not replacing cloud. It is intensifying the importance of cloud while also changing how value is measured. Training, tuning, deploying, and governing AI systems require immense computational scale, specialized infrastructure, distributed data access, and operational consistency. Public cloud providers are well positioned to offer those capabilities, particularly with GPUs, AI platforms, managed model services, and data integration tools.
But this is not a repeat of the early cloud era. Enterprises are more sober now. They know the importance of cost, latency, and data gravity. They know that governance and accountability matter more in AI than perhaps anywhere else in modern IT. The role of cloud in the AI race is therefore foundational, but not absolute. Some AI workloads will run in public cloud. Some will be distributed across edge computing environments. Some will remain in private environments for reasons of sovereignty, economics, or control. The key is not to force a universal answer. The key is to create an architecture that aligns AI ambitions with operational reality.
Cloud should play the role it has gradually earned: not as a religion, but as a strategic utility. For AI, the cloud is where many enterprises will source scale, experimentation speed, global reach, and managed innovation. The winning organizations understand where cloud creates leverage and where other operating models make more sense.
Changing how enterprises think
The real story of the past 20 years is not just that AWS launched S3 and helped popularize infrastructure as a service. It is that cloud changed enterprise behavior. It normalized service consumption over asset ownership. It moved architecture toward abstraction, automation, and modularity. It forced IT organizations to broker capability rather than build everything from scratch. It redefined speed as a core competitive requirement.
And now, as AI becomes the next forcing function, cloud stands less as a novelty and more as the platform on which the next era will be built. That is a remarkable outcome for something that, in many ways, started with the old idea that computing could be delivered remotely on a subscription basis. We have been heading here for longer than many people realize. In the past two decades, led in large measure by AWS and the broader hyperscale movement it accelerated, cloud has evolved from a gamble to an indispensable foundation.
Hard to believe? Yes. But also inevitable in retrospect.
{kind=link}
Write cleaner and faster Python code 19 Jun 2026, 4:00 am
Meta’s long-awaited Pyrefly linter is out in a 1.0 version, and the forthcoming Python 3.15 has a super-efficient sampling profiler. Plus we have a comprehensive rundown of Python’s indispensable virtual environments — and a warning about a novel breed of malware that exploits Python’s package ecosystem.
Top picks for Python readers on InfoWorld
How to use virtual environments in Python
Isolate and protect your Python projects from each other, and empower them to do more, with virtual environments and their native-to-Python tooling.
Pyrefly 1.0: A fast, forward-looking Python linter
The first full release of Meta’s long-awaited linting and type checking tool for Python delivers speed and offers advanced features for type-checking PyTorch and Django projects.
Hands-on with the new sampling profiler in Python 3.15
Among Python 3.15’s best new features is a sampling profiler, for instrumenting your code and finding its bottlenecks with a minimum of performance impact or fuss. See up-close how it works.
All about Hades, the supply-chain malware that hides in Python packages
It hides in Python packages. It replicates itself across systems. It fools LLM-based code analysis tools into ignoring it. And there may be a lot more like it to come.
More good reads and Python updates elsewhere
Python Steering Council calls for temporary pause on JIT project
The requested pause stays in place until a proper Standards Track PEP lands for the experimental JIT (just-in-time) compiler, the better to describe how the JIT will be a formal and supported part of Python.
Pyodide 314.0: Pyodide packages on PyPI
Thanks to PEP 783, Python packages built with Pyodide (Python ported to WebAssembly) can be installed straight from PyPI instead of through Pyodide — another step closer to Py-on-Wasm becoming an everyday thing.
All about that Python 3.14 garbage collection rigmarole
A new garbage collector introduced in Python 3.14 was yanked at the last minute due to reports of higher memory usage. Here’s a deep dive into what changed for the worse and why.
Are you really expected to run five type checkers now?
No, but you should keep your options open. This blog post from a Pyrefly contributor recommends choosing one of the major offerings (Mypy, Pyrefly, Pyright, ty, Zuban, etc.), but also getting to know the others too.
{kind=link}
Page processed in 1.876 seconds.
Powered by SimplePie 1.3.1, Build 20131001021811. Run the SimplePie Compatibility Test. SimplePie is © 2004–2026, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.